
 Back
Back
Search API use cases
Full-text document search
SeekStorm search API offers web-scale, real-time, full-text, instant search for your documents. Even if your organization has millions or billions of documents, at different locations, with thousands of concurrent users who need results within milliseconds, the latest changes are reflected instantly in real-time.
SeekStorm excellent performance and scalability offers 5…10x speed compared to industry-standard solutions like Lucene. SeekStorm not only excels performance-wise but is also very affordable with 30x more queries & docs per dollar spent compared to other SaaS solutions.
A document is any valid JSON document, with any number of fields (key value-pairs), where the key is a string and the value is of any valid JSON type (string, number, array, boolean, object). For every field, we can define whether it should be stored, indexed, and included in the search results.
Product search
SeekStorm search API enables rich product results that let you attract potential buyers while they are searching for items to buy on your website. Realtime indexing ensures the freshness of your product information, so your customers find the relevant, current items they're looking for.
Spelling correction, auto suggestion, query completion and instant search are all assisting the user while searching and enable a smooth and frictionless search experience.
Faceted search allows to restrict the search to specific fields, e.g. to titel, URL or domain, author or product category. This allows your customer to narrow down the results efficiently according to their specific requirements, without overwhelming them with irrelevant results.
Focused crawler
A focused crawler is a web crawler that collects Web pages that satisfy some specific property (e.g. domain, URL prefix), by carefully prioritizing the crawl frontier and the link selection and exploration. For each website you want to include in your search you have to define a separate crawl job. You can specify additional URL path filters. By excluding webpages beyond the focus of your interest, you can increase the relevance of the search results, indexing speed, query speed, and reduce the index size.All crawled web pages from different websites and crawl jobs can be indexed to the same index or separate indices. The aggregated results can be instantly searched in real-time, even while the crawl job is still running. You can define the re-crawl period in minutes to ensure the index stays up to date.
SeekStorm crawling is intended for consensual crawling only. You need to own or obtain all rights and licenses required to crawl the content and you need to obey all restrictions and limits imposed by the website owner. SeekStorm doesn't allow, encourage nor provide tools (e.g. proxies) to break restrictions imposed by the website owner.
Semantic entity extraction
The extraction of specific entities as names, product names, trademarks, dates, geographical names from an unstructured text at scale as a first step requires obtaining the webpages from the web, stripping the HTML markup, and extracting the raw text. The documents are then converted to structured JSON documents, stored and indexed. Then they are readily available for post-processing with deep learning, semantical analysis, or other NLP tools.Data extraction for deep learning
SeekStorm automatically extracts structured data, as defined by schema.org and Open Graph protocol, at scale from any number of webpages, without requiring any code. SeekStorm turns unstructured websites in structured data, to be consumed and processed by your data science, data mining, artificial intelligence, machine learning, and deep learning algorithms.
Web monitoring
The monitoring of websites on the Internet for trend analysis, competitive intelligence trademark infringement, stock prediction, threat intelligence, and alerts require a continuous observation of domains of interest trough crawling, text extraction, storing, and full-text indexing. This is an essential part of the toolchain before the customer can apply any sophisticated post-processing step to further analyze the raw data.Site search
You can implement a site search for your own website or for any other website you want to have searchable. So, even if the website owner did not implement site search you could search the website throughout within a few minutes. If you intend to make the site search publicly available make sure you own or obtain all necessary rights.
Custom News search
You can implement a custom news search API by combining SeekStorm search as a service with SeekStorm crawler as a service. For each news source or website, you want to include in your search you have to define a separate crawl job. All crawled web pages from different websites and crawl jobs will be indexed to the same index. The aggregated results can be instantly searched in real-time, even while the crawl job is still running. You can define the re-crawl period in minutes to ensure the index stays up to date. Make sure that you own or obtain all necessary rights to the content according to your local law to index it.
Custom Web search
You can implement a custom web search API by combining SeekStorm search as a service with SeekStorm crawler as a service. For each website, you want to include in your search you have to define a separate crawl job. All crawled web pages from different websites and crawl jobs will be indexed to the same index. The aggregated results can be instantly searched in real-time, even while the crawl job is still running. You can define the re-crawl period in minutes to ensure the index stays up to date. Make sure that you own or obtain all necessary rights to the content according to your local law to index it.
Wikipedia search
The whole English Wikipedia with more than 6 million pages can be indexed within a few minutes using SeekStorm search API to index a Wikipedia JSON dump. While you could also crawl the Wikipedia using SeekStorms crawl API this would be ineffective and take more time.
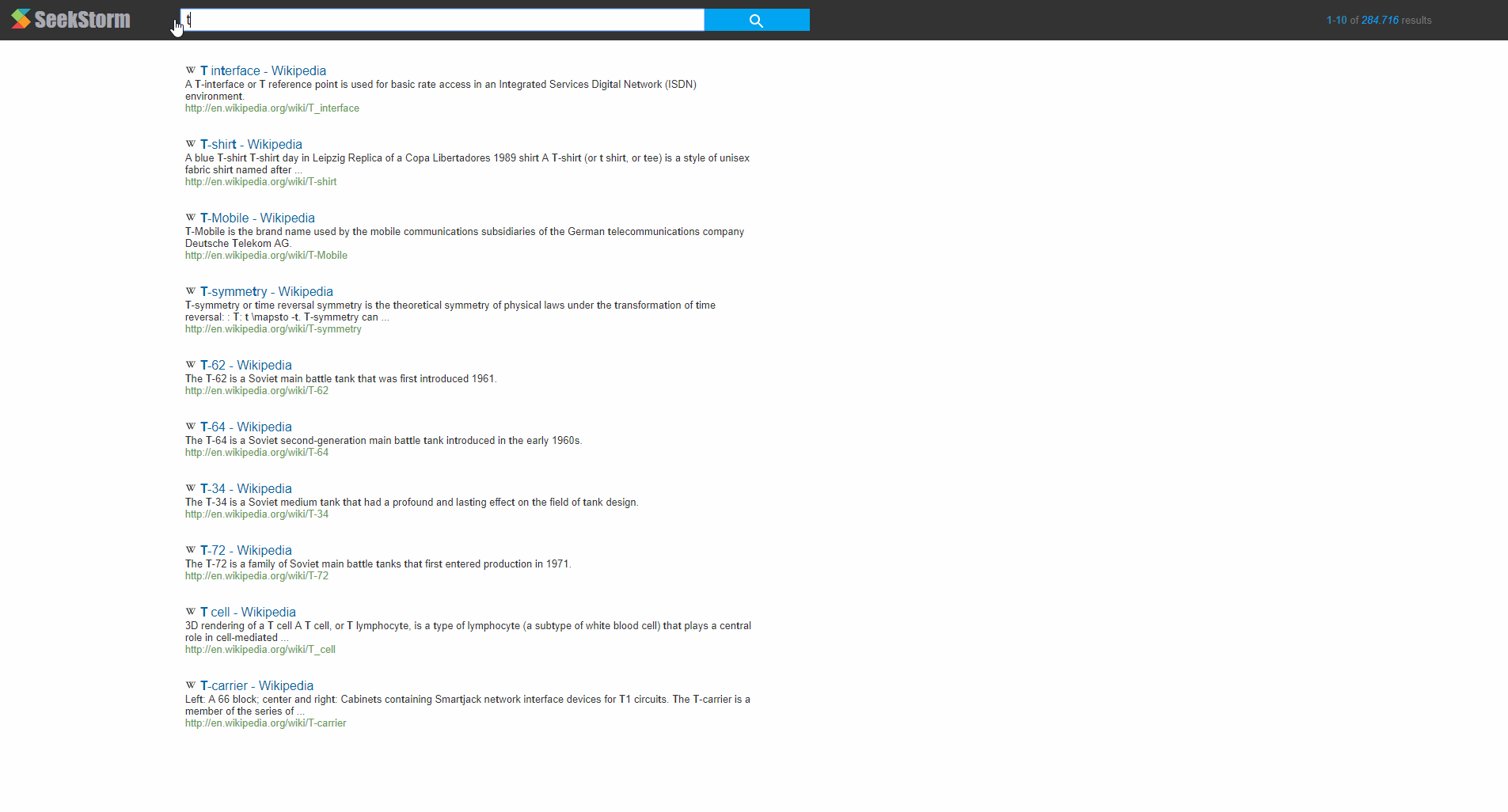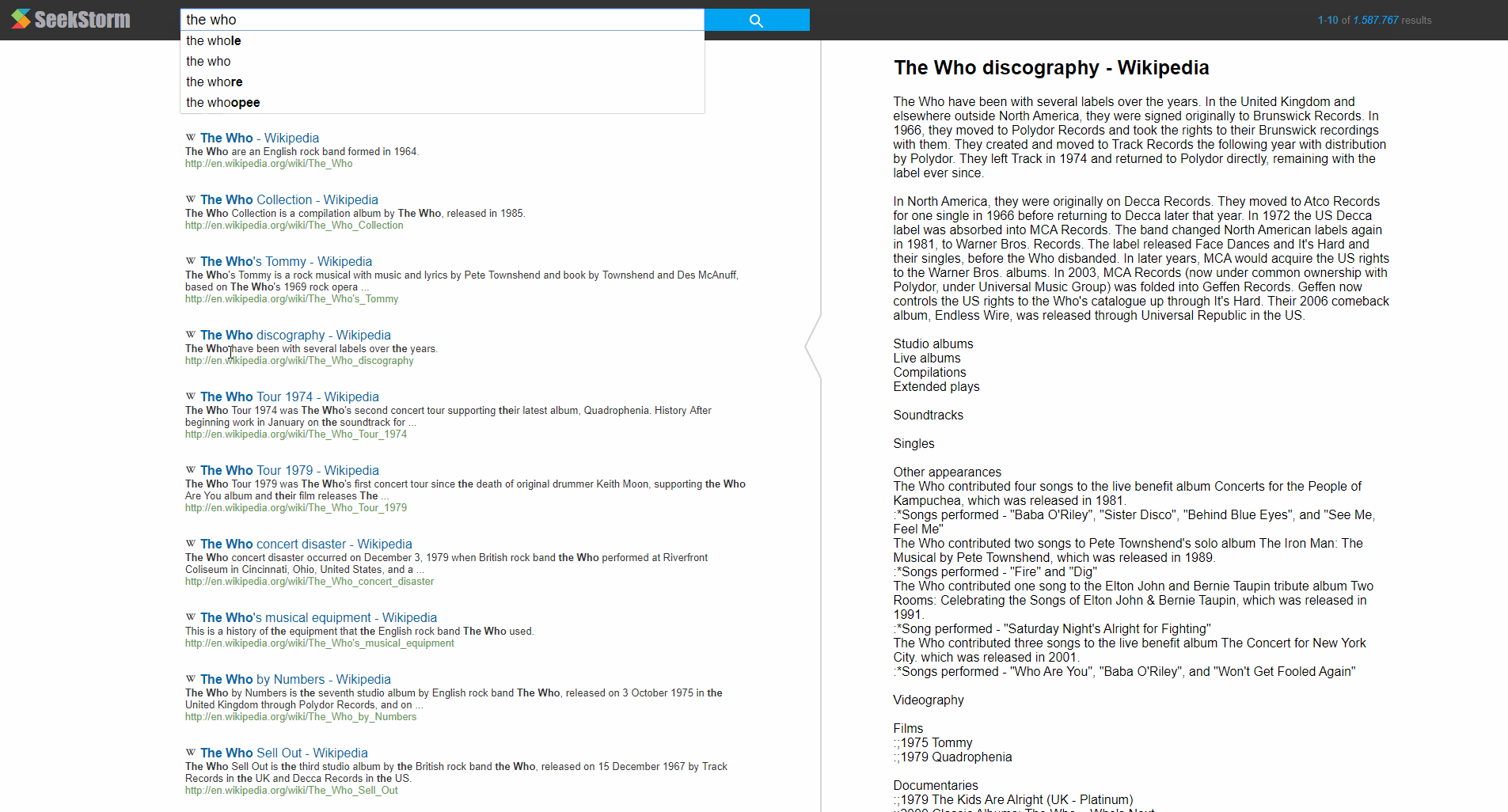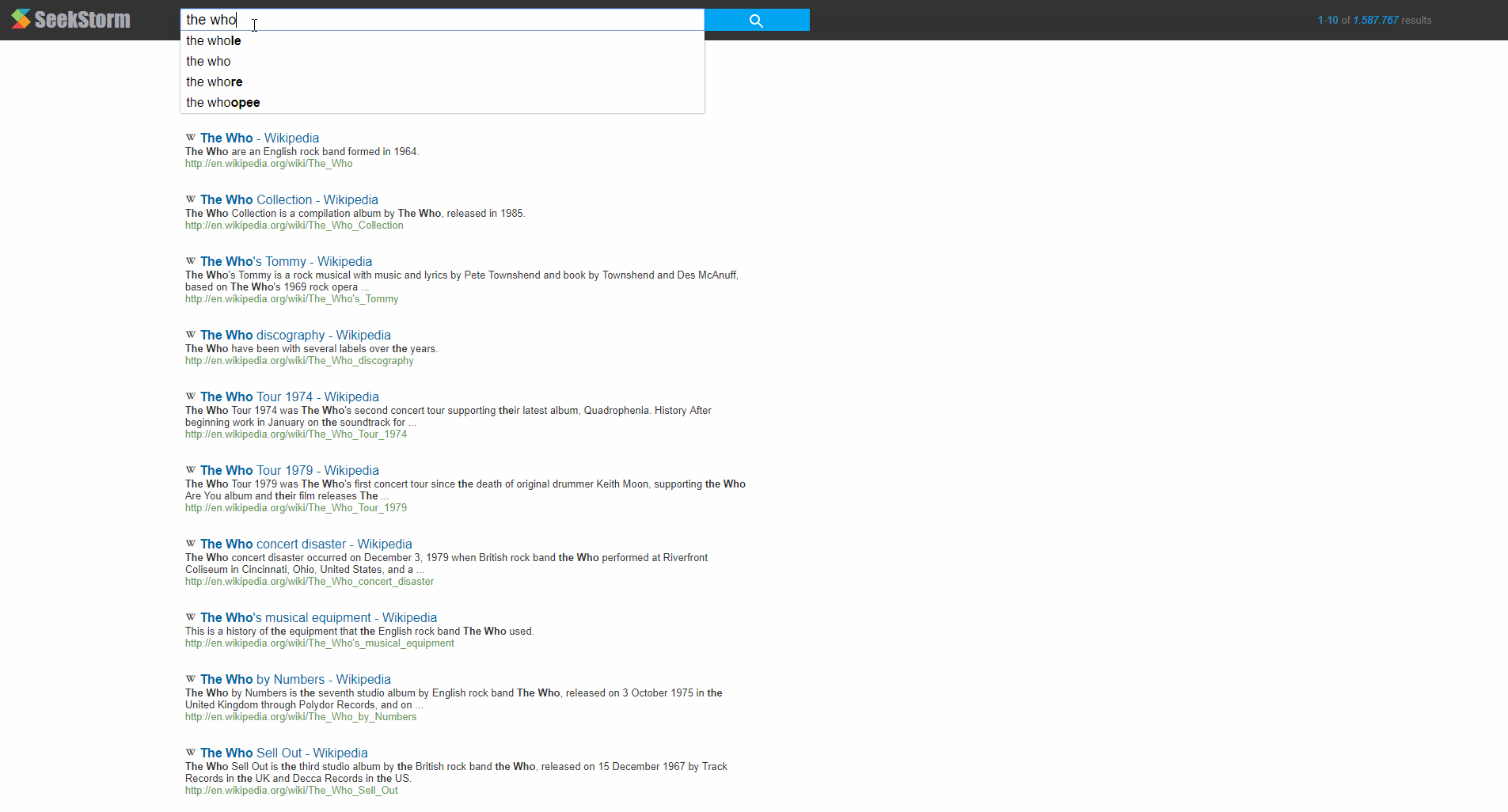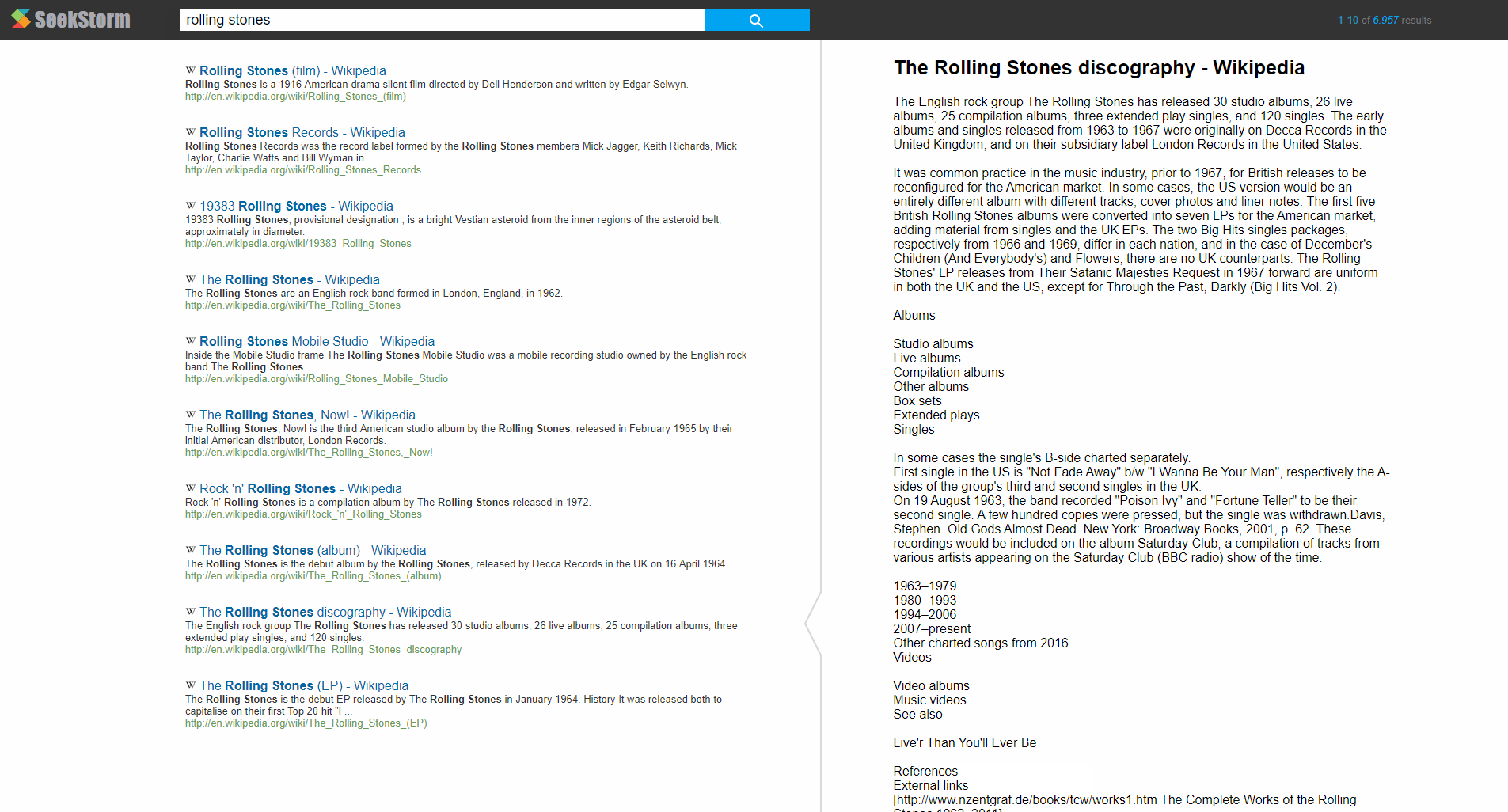
Example: Instant search in English Wikipedia (6 million documents, 70 GB)
Please note the implicit phrase search when searching for 'rolling stones' or 'the who'. The user is not required to explictly use quotes. SeekStorm will automatically rank results higher, where all search terms are close and the order specified in the query.
The last phrase is challenging because both terms are extremely frequent, present in almost every web page. Those terms are called 'stop words'. Many search engines are excluding stop words from indexing and searching, making it impossible to search for phrases containing them.
This example also shows automatic query suggestion and query completion and instant search in action. The results are dispayed instantly before the user has even typed the complete query and without the user is required to hit der enter key.
Scrape public gazettes
Public gazettes such as official gazette, government gazette, federal gazette, law gazette, health gazette, stock exchange gazette publish information on a publicly acessible website. Seekstorms crawl API and search API can be combined to monitor, crawl, scrape and aggregate those informations and make them seachable in real-time.
Scraping public listing
Public listings for auctions, bids and company registrations can be monitored, crawled, scraped, aggregated and made seachable in real-time by combining Seekstorm Crawl API and search API.
Open-Source Intelligence (OSINT)
SeekStorm provides a high-performance infrastructure for collecting, indexing, and searching data accessible in publicly available sources to be used in an intelligence context. SeekStorm's high-performance, focused crawler allows targeting and monitoring those areas on the Internet where information is expected to occur first.
SeekStorm's real-time and web-scale search enables even an index with billions of documents to be searched within milliseconds, from thousand users in parallel.
 Blog
Blog
 Twitter
Twitter
 LinkedIn
LinkedIn