
 Back
Back
Getting started
Introduction
This is a quick start guide on how to create a SeekStorm account and project. We will show you how to use the dashboard and the REST API to create an index, index documents, and query documents.
With our dashboard, you can index and search your documents in less than 5 minutes, without a single line of code.
With our REST API, you can integrate the incredible speed of SeekStorm into your application, with a few lines of code.
Setting up a project
SeekStorm distinguishes accounts, projects with an assigned plan, indices, documents with fields, and crawljobs.
A user can sign up for a single account. Within that account, he can create multiple projects. For every project, the user can choose one of the plans which differ in price and capacity. Every project is assigned a distinct API key, required to authorize the user to carry out operations within this project. Within a project, multiple indices can be created. To each index, multiple documents can be created, stored, and indexed. Also, multiple crawljobs can be created for each index.
Hierarchy
Account Projects/Plans Indices Documents Fields Crawljobs
Step by step
Most operations can be done either manually in the dashboard or programmatically via REST API.
Accounts can be created and plans chosen in the dashboard only.
Some API endpoints are not yet available in the dashboard and can be used via REST API only.
- Create account:
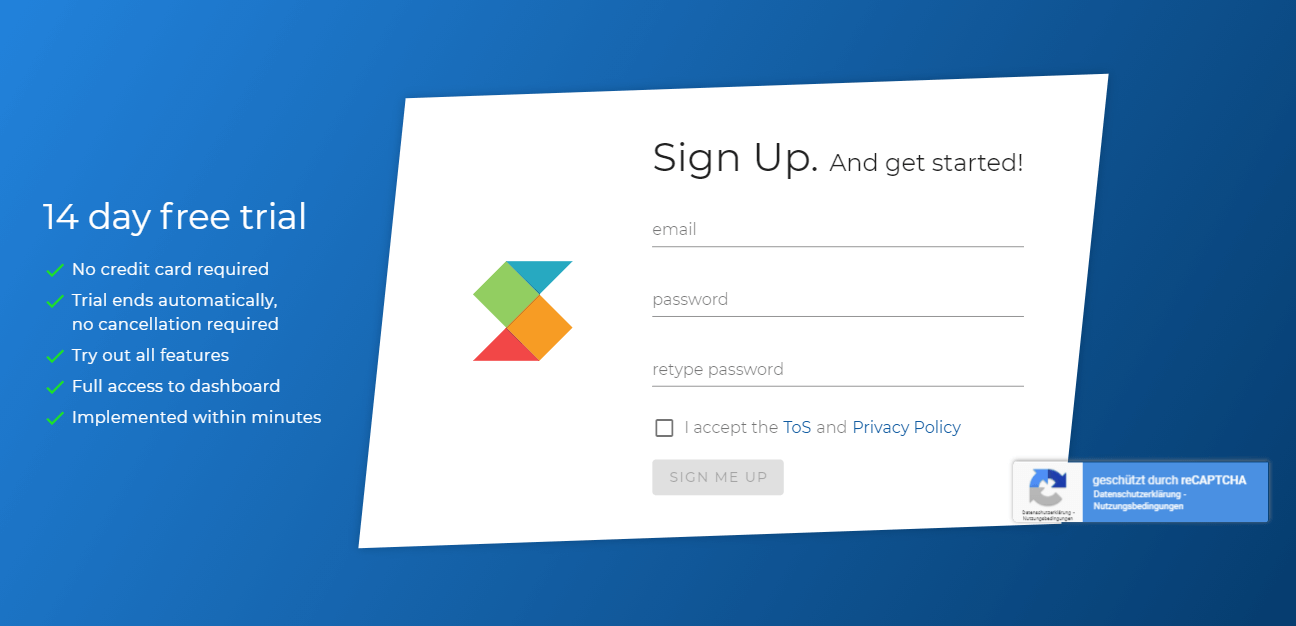
Click on "FREE TRIAL" in the top-right corner or "SIGNUP" for Basic/Pro/Business plan below the pricing table to create an account.
Just enter your email address and a secure password - it's that simple!
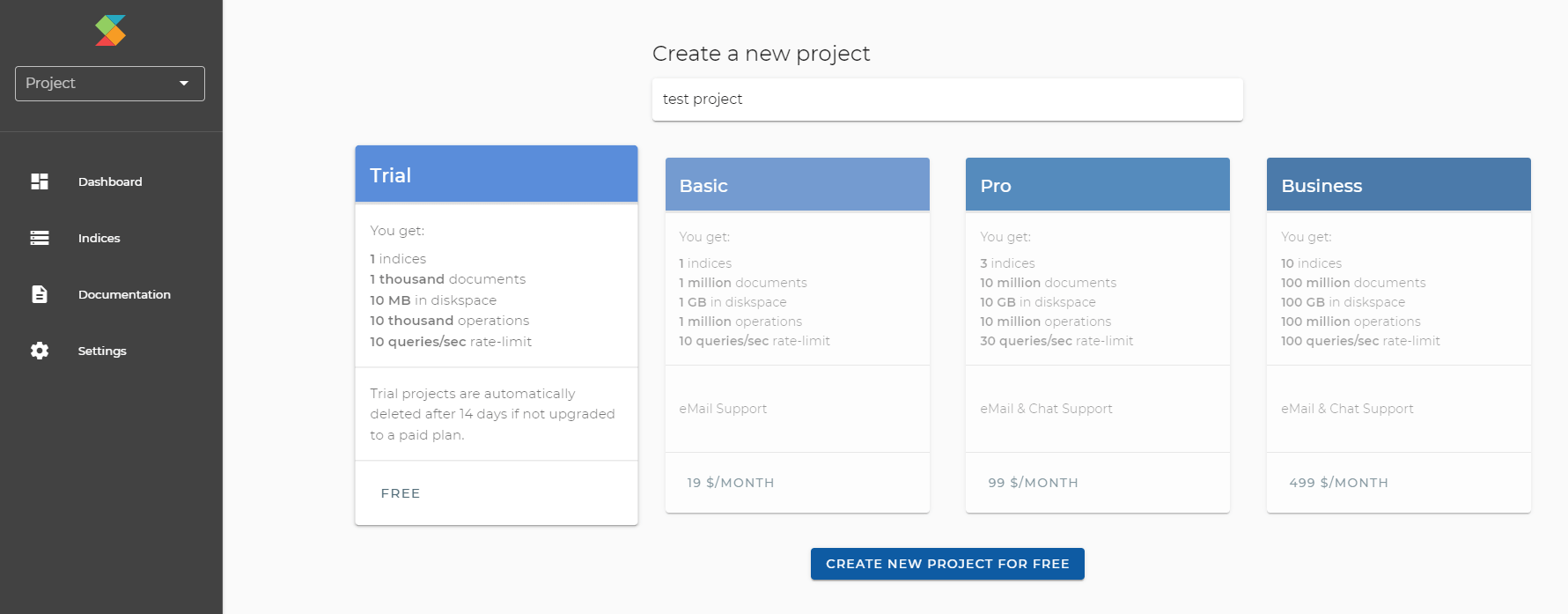
- Create project: Within your account, you create one or multiple projects within the dashboard. For each project, you can choose one of the 4 plans (Trial/Basic/Pro/Business).
The 14-day Free Trial allows you to test all features for free. No credit card required, you won't be charged at any time. The trial ends automatically after 14 days. No manual cancelation is required. Within the 14 days you can choose to upgrade to a paid plan and keep your data.
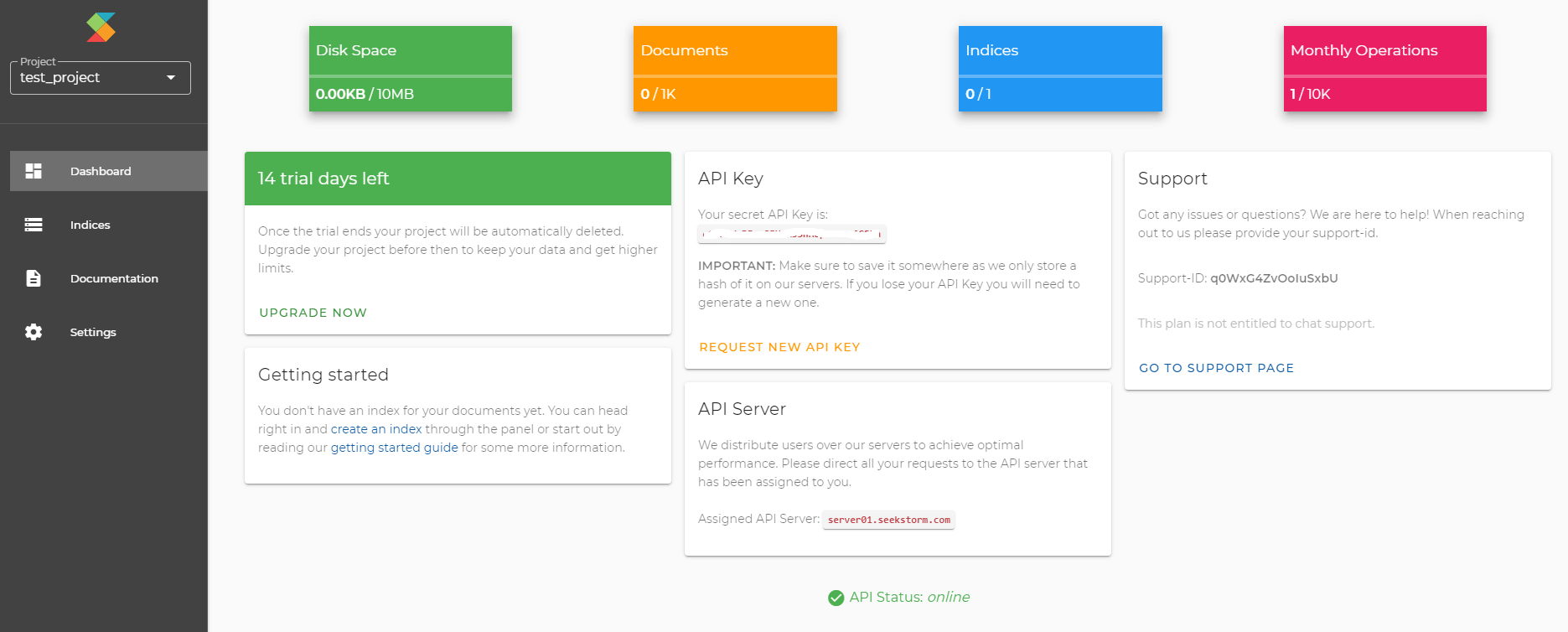
Dashboard: After creating a project, you are forwarded to the dashboard. There every project is assigned a distinct API key, required to authorize the user to carry out operations within this project, and an API server URL. There you will also find the support ID if you got questions or need help. The dashboard also displays stats on how many indices, documents, diskspace, and operations of your plan you have already consumed.
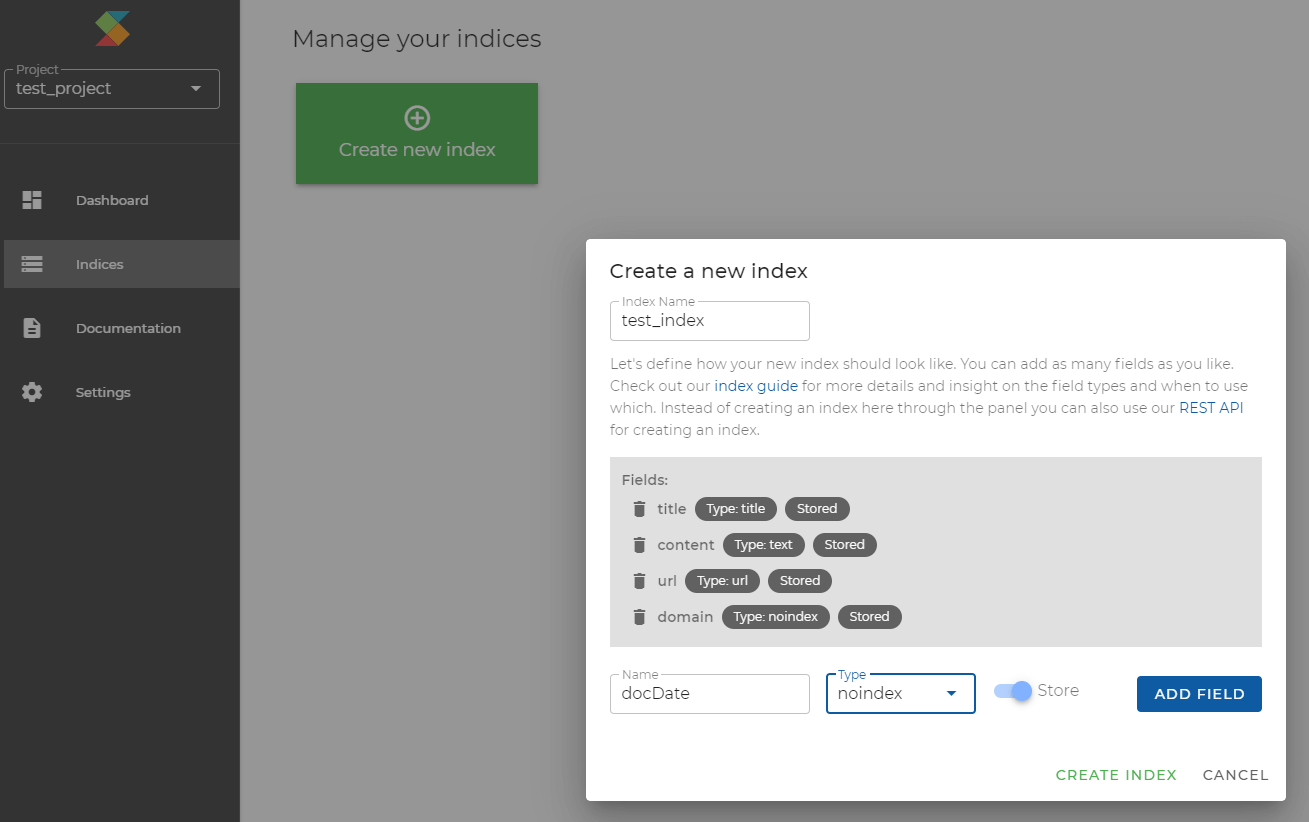
- Create index: Within your project, you create one or multiple indices, either within the dashboard or via REST API. For each project, you define an index structure, i.e. what fields of
which field types the index should contain, and whether the fields should be stored, indexed, or both.
- Manage index: Once you have created an index you can manage it: Index documents, explore documents or delete the index again.
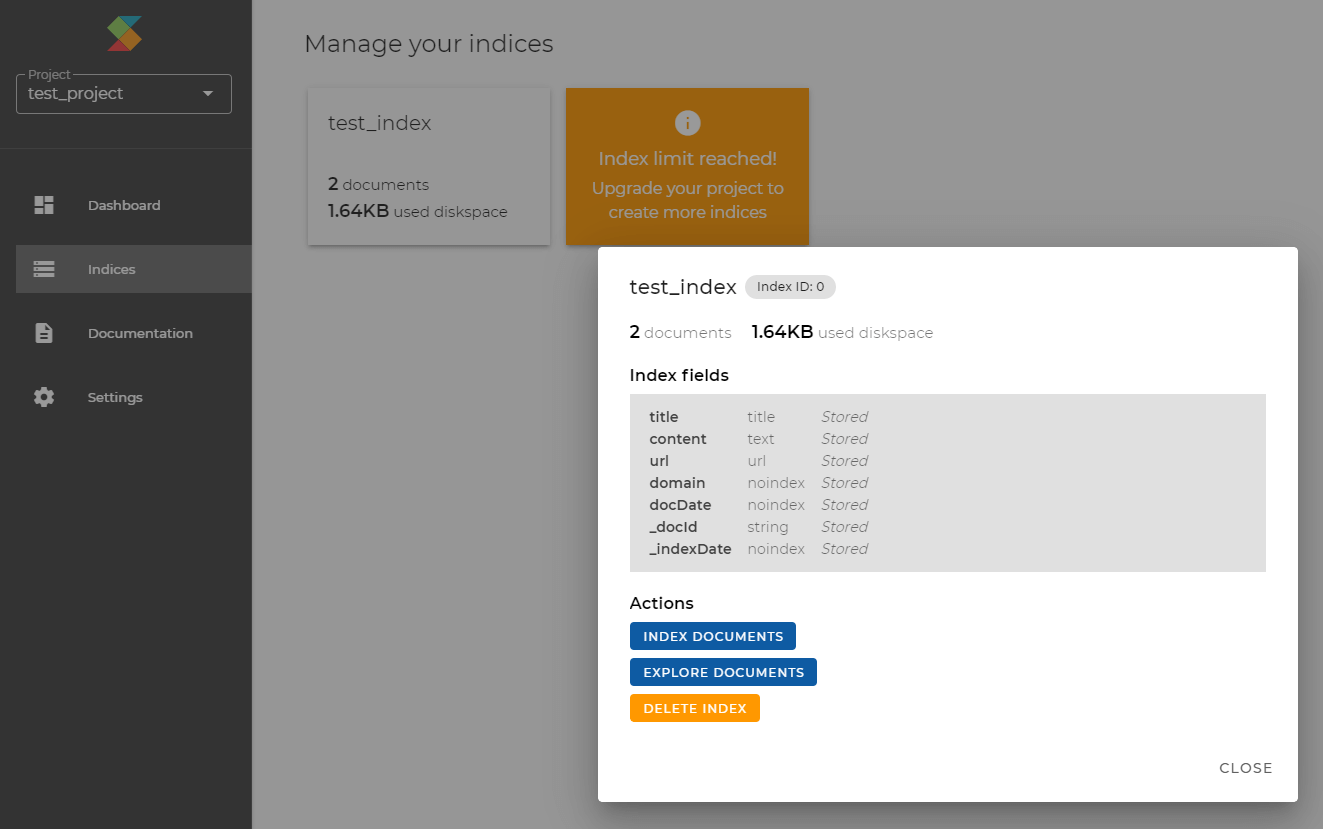
- Create & index documents: Then you are ready to index documents into an index, either within the dashboard or via REST API.
In the dashboard, you can either manually create a document derived
from your index definition and fill in the field values. Or you can upload a JSON document from your local computer.
Alternatively, you may use our REST API to upload a single JSON document or a list of JSON documents.
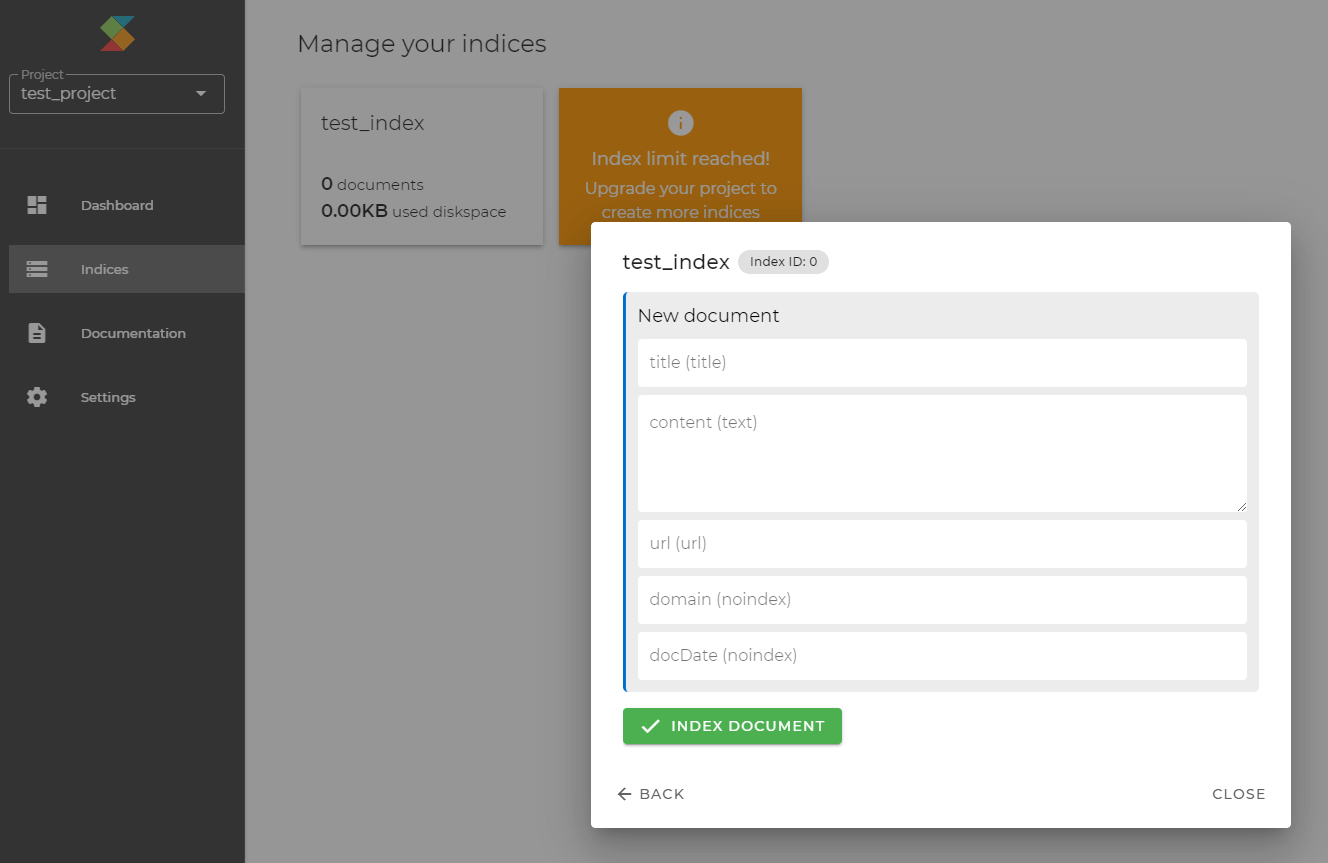
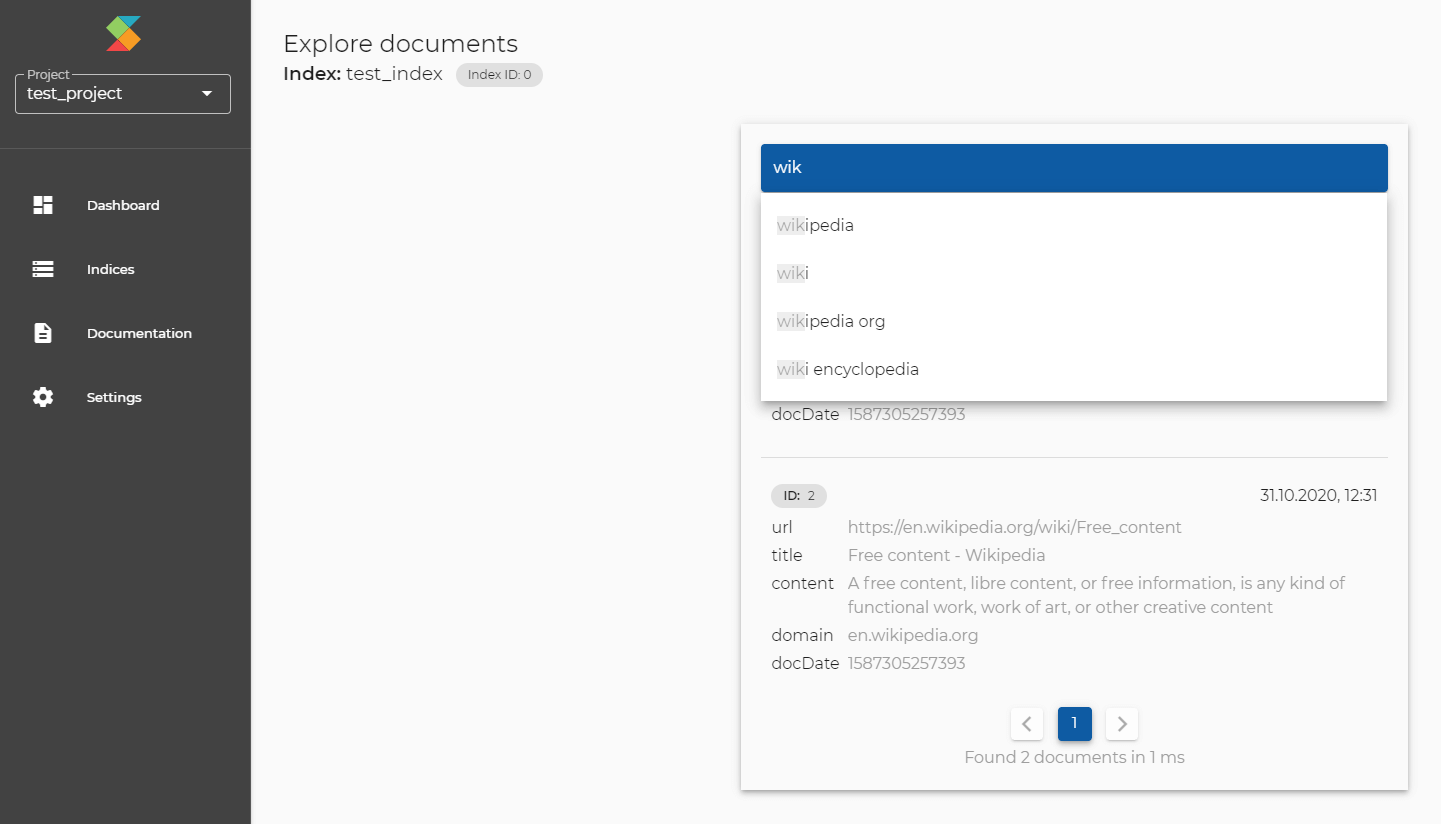
- Explore & query documents: Once you have indexed some documents, either via dashboard or via API, you can browse them or search them with a query.
With a query, the results are ordered by relevance. With an empty query, the results are ordered by recency.
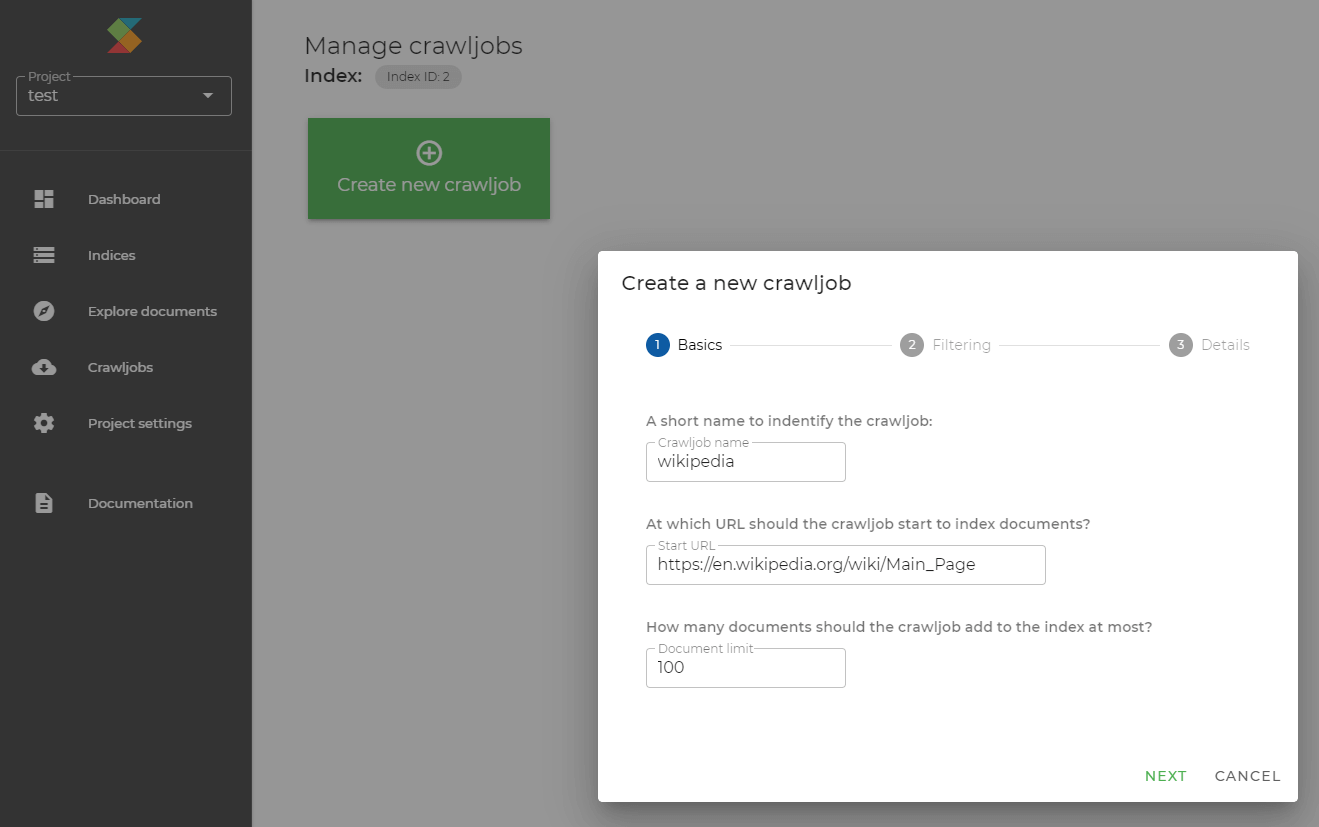
- Create crawljob: Alternatively to creating and indexing your own documents, you might want to index web pages from the Internet.
You can instruct SeekStorm's crawler to do this for you by creating a crawljob, either via the dashboard or via API.
Before creating a crawljob make sure you have already created an index that contains all mandatory fields required by a crawljob.
After the crawljob is created and the crawling is finished, you can explore and query the crawled and indexed web pages as described above.
You can use the urlFilter for focused crawling that achieves higher relevance by filtering out unwanted content.
Code examples
With our REST API and just a few lines of code, you can integrate SeekStorm's incredible speed and scalability into your application. Some examples with Curl, C#, C++, Go, Java, Javascript, PHP, Python, Rust, Swift for basic operations:
- Create index
- Get index (stats)
- Index document
- Get document
- Query documents
- Create crawljob
- Get crawljob (status)
Curl
In Microsoft Windows replace any line-ending backslash (\) character with the caret (^) character.
Create index (see documentation)
curl https://server01.seekstorm.com/indices \
--header "apiKey: YOUR-API-KEY" \
--header "Content-Type: application/json" \
--data "{\"name\":\"name1\",\"createAutocompleteDictionary\":true,\"fields\":{ \"title\":{ \"store\":true,\"type\":\"title\"},\"content\":{ \"store\":true,\"type\":\"text\"},\"url\":{\"store\":true,\"type\":\"url\"},\"domain\":{ \"store\":true,\"type\":\"noindex\"},\"docDate\":{ \"store\":true,\"type\":\"noindex\"}}}"
Get index (see documentation)
curl --get https://server01.seekstorm.com/indices/0 \ --header "apiKey: YOUR-API-KEY"
Index document from string (see documentation)
curl https://server01.seekstorm.com/indices/0/documents \
--header "apiKey: YOUR-API-KEY" \
--header "Content-Type: application/json" \
--data "{\"url\": \"https://en.wikipedia.org/wiki/Encyclopedia\", \"domain\": \"en.wikipedia.org\", \"title\": \"Encyclopedia - Wikipedia\", \"content\": \"An encyclopedia or encyclopaedia (British English) is a reference work or compendium providing summaries of knowledge.\"}"
Index document from file (see documentation)
curl https://server01.seekstorm.com/indices/0/documents \ --header "apiKey: YOUR-API-KEY" \ --header "Content-Type: application/json" \ --data-binary @document.json
Get document (see documentation)
curl --get https://server01.seekstorm.com/indices/0/documents/1 \ --header "apiKey: YOUR-API-KEY"
Query documents (see documentation)
curl --get https://server01.seekstorm.com/indices/0/documents \ --data-urlencode "query=wikipedia test" \ --data "offset=0" \ --data "length=10" \ --data "instant=true" \ --data "correction=true" \ --data "completion=true" \ --data "result=title" \ --data "result=content" \ --data "result=url" \ --data "summary=content" \ --header "Content-Type: application/json" \ --header "apiKey: YOUR-API-KEY"
Create crawljob from string (see documentation)
curl https://server01.seekstorm.com/indices/0/crawljobs \
--header "apiKey: YOUR-API-KEY" \
--header "Content-Type: application/json" \
--data "{\"name\": \"wikipedia\",\"startUrl\": \"https://en.wikipedia.org/wiki/Main_Page\",\"urlFilter\":{\"segmentNumber\": 1,\"segmentFilter\": [\"wiki\"]}, \"timeout\": 10, \"politeTimeParallelThreads\": 1, \"recrawlTime\": 0, \"keytextOnly\": true, \"maxDocs\": 100}"
Create crawljob from file (see documentation)
curl https://server01.seekstorm.com/indices/0/crawljobs \ --header "apiKey: YOUR-API-KEY" \ --header "Content-Type: application/json" \ --data-binary @crawljob.json
Get crawjob (see documentation)
curl --get https://server01.seekstorm.com/indices/0/crawljobs/0 \ --header "apiKey: YOUR-API-KEY"
C#
Create HttpClient instance
using System;
using System.Net;
using System.Net.Http;
using System.Text;
HttpClient httpClient;
var handler = new HttpClientHandler
{
AutomaticDecompression = DecompressionMethods.Brotli | DecompressionMethods.GZip | DecompressionMethods.Deflate
};
httpClient = new HttpClient(handler);
httpClient.DefaultRequestVersion = new Version(2, 0);
httpClient.DefaultRequestHeaders.Connection.Add("Keep-Alive");
httpClient.DefaultRequestHeaders.Add("Cache-Control", "no-cache");
httpClient.DefaultRequestHeaders.Add("apiKey", "YOUR-API-KEY");
Create index (see documentation)
string createIndexRequest = "{\"name\":\"name1\",\"createAutocompleteDictionary\":true,\"fields\":{ \"title\":{ \"store\":true,\"type\":\"title\"},\"content\":{ \"store\":true,\"type\":\"text\"},\"url\":{\"store\":true,\"type\":\"url\"},\"domain\":{ \"store\":true,\"type\":\"noindex\"},\"docDate\":{ \"store\":true,\"type\":\"noindex\"}}}";
using (var requestMessage = new StringContent(createIndexRequest, Encoding.UTF8, "application/json"))
{
var responseMessage = httpClient.PostAsync(new Uri("https://server01.seekstorm.com/indices"), requestMessage).Result;
string responseBody = responseMessage.Content.ReadAsStringAsync().Result;
HttpStatusCode statusCode = responseMessage.StatusCode;
Console.WriteLine("Status: " + statusCode.ToString() + " Response: " + responseBody);
}
Get index (see documentation)
using (var requestMessage = new HttpRequestMessage(HttpMethod.Get, new Uri("https://server01.seekstorm.com/indices/0")))
{
requestMessage.Headers.Add("Cache-Control", "no-cache, no-store");
var responseMessage = httpClient.SendAsync(requestMessage).Result;
string responseBody = responseMessage.Content.ReadAsStringAsync().Result;
HttpStatusCode statusCode = responseMessage.StatusCode;
Console.WriteLine("Status: " + statusCode.ToString() + " Response: " + responseBody);
}
Index document from string (see documentation)
string document = "{\"url\": \"https://en.wikipedia.org/wiki/Encyclopedia\", \"domain\": \"en.wikipedia.org\", \"title\": \"Encyclopedia - Wikipedia\", \"content\": \"An encyclopedia or encyclopaedia (British English) is a reference work or compendium providing summaries of knowledge.\"}";
using (var requestMessage = new StringContent(document, Encoding.UTF8, "application/json"))
{
var responseMessage = httpClient.PostAsync(new Uri("https://server01.seekstorm.com/indices/0/documents"), requestMessage).Result;
string responseBody = responseMessage.Content.ReadAsStringAsync().Result;
HttpStatusCode statusCode = responseMessage.StatusCode;
Console.WriteLine("Status: " + statusCode.ToString() + " Response: " + responseBody);
}
Get document (see documentation)
using (var requestMessage = new HttpRequestMessage(HttpMethod.Get, new Uri("https://server01.seekstorm.com/indices/0/documents/1")))
{
requestMessage.Headers.Add("Cache-Control", "no-cache, no-store");
var responseMessage = httpClient.SendAsync(requestMessage).Result;
string responseBody = responseMessage.Content.ReadAsStringAsync().Result;
HttpStatusCode statusCode = responseMessage.StatusCode;
Console.WriteLine("Status: " + statusCode.ToString() + " Response: " + responseBody);
}
Query documents (see documentation)
using (var requestMessage = new HttpRequestMessage(HttpMethod.Get, new Uri("https://server01.seekstorm.com/indices/1/documents?query="+ System.Web.HttpUtility.UrlEncode("wikipedia") + "&offset=0&length=10&instant=true&correction=true&completion=true&result=title&result=content&result=url&summary=content")))
{
requestMessage.Headers.Add("Cache-Control", "no-cache, no-store");
var responseMessage = httpClient.SendAsync(requestMessage).Result;
string responseBody = responseMessage.Content.ReadAsStringAsync().Result;
HttpStatusCode statusCode = responseMessage.StatusCode;
Console.WriteLine("Status: " + statusCode.ToString() + " Response: " + responseBody);
}
Create crawljob from string (see documentation)
string createCrawljobRequest = "{\"name\": \"wikipedia\",\"startUrl\": \"https://en.wikipedia.org/wiki/Main_Page\",\"urlFilter\":{\"segmentNumber\": 1,\"segmentFilter\": [\"wiki\"]}, \"timeout\": 10, \"politeTimeParallelThreads\": 1, \"recrawlTime\": 0, \"keytextOnly\": true, \"maxDocs\": 100}";
using (var requestMessage = new StringContent(createCrawljobRequest, Encoding.UTF8, "application/json"))
{
var responseMessage = httpClient.PostAsync(new Uri("https://server01.seekstorm.com/indices/0/crawljobs"), requestMessage).Result;
string responseBody = responseMessage.Content.ReadAsStringAsync().Result;
HttpStatusCode statusCode = responseMessage.StatusCode;
Console.WriteLine("Status: " + statusCode.ToString() + " Response: " + responseBody);
}
Get crawjob (see documentation)
using (var requestMessage = new HttpRequestMessage(HttpMethod.Get, new Uri("https://server01.seekstorm.com/indices/0/crawljobs/0")))
{
requestMessage.Headers.Add("Cache-Control", "no-cache, no-store");
var responseMessage = httpClient.SendAsync(requestMessage).Result;
string responseBody = responseMessage.Content.ReadAsStringAsync().Result;
HttpStatusCode statusCode = responseMessage.StatusCode;
Console.WriteLine("Status: " + statusCode.ToString() + " Response: " + responseBody);
}
C++
Go
Java
Create HttpClient instance
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.net.URI;
import java.net.URLEncoder;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.time.Duration;
HttpClient httpClient = HttpClient.newBuilder()
.version(HttpClient.Version.HTTP_2)
.connectTimeout(Duration.ofSeconds(10))
.build();
Create index (see documentation)
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://server01.seekstorm.com/indices"))
.header("Content-Type", "application/json")
.header("apiKey", "YOUR-API-KEY")
.POST(HttpRequest.BodyPublishers.ofString("{\"name\":\"name1\",\"createAutocompleteDictionary\":true,\"fields\":{ \"title\":{ \"store\":true,\"type\":\"title\"},\"content\":{ \"store\":true,\"type\":\"text\"},\"url\":{\"store\":true,\"type\":\"url\"},\"domain\":{ \"store\":true,\"type\":\"noindex\"},\"docDate\":{ \"store\":true,\"type\":\"noindex\"}}}"))
.build();
HttpResponse response = httpClient.send(request,HttpResponse.BodyHandlers.ofString());
System.out.println("Status: "+response.statusCode() + " Response: " +response.body());
Get index (see documentation)
HttpRequest request = HttpRequest.newBuilder()
.GET()
.uri(URI.create("https://server01.seekstorm.com/indices/0"))
.header("Cache-Control", "no-cache, no-store")
.header("apiKey", "YOUR-API-KEY")
.build();
HttpResponse response = httpClient.send(request,HttpResponse.BodyHandlers.ofString());
System.out.println("Status: "+response.statusCode() + " Response: " +response.body());
Index document from string (see documentation)
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://server01.seekstorm.com/indices/0/documents"))
.header("Content-Type", "application/json")
.header("apiKey", "YOUR-API-KEY")
.POST(HttpRequest.BodyPublishers.ofString("{\"url\": \"https://en.wikipedia.org/wiki/Encyclopedia\", \"domain\": \"en.wikipedia.org\", \"title\": \"Encyclopedia - Wikipedia\", \"content\": \"An encyclopedia or encyclopaedia (British English) is a reference work or compendium providing summaries of knowledge.\"}" ))
.build();
HttpResponse response = httpClient.send(request,HttpResponse.BodyHandlers.ofString());
System.out.println("Status: "+response.statusCode() + " Response: " +response.body());
Get document (see documentation)
HttpRequest request = HttpRequest.newBuilder()
.GET()
.uri(URI.create("https://server01.seekstorm.com/indices/0/documents/1"))
.header("Cache-Control", "no-cache, no-store")
.header("apiKey", "YOUR-API-KEY")
.build();
HttpResponse response = httpClient.send(request,HttpResponse.BodyHandlers.ofString());
System.out.println("Status: "+response.statusCode() + " Response: " +response.body());
Query documents (see documentation)
HttpRequest request = HttpRequest.newBuilder()
.GET()
.uri(URI.create("https://server01.seekstorm.com/indices/1/documents?query="+URLEncoder.encode("wikipedia",StandardCharsets.UTF_8.toString())+"&offset=0&length=10&instant=true&correction=true&completion=true&result=title&result=content&result=url&summary=content"))
.header("Cache-Control", "no-cache, no-store")
.header("apiKey", "YOUR-API-KEY")
.build();
HttpResponse response = httpClient.send(request,HttpResponse.BodyHandlers.ofString());
System.out.println("Status: "+response.statusCode() + " Response: " +response.body());
Create crawljob from string (see documentation)
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://server01.seekstorm.com/indices/0/crawljobs"))
.header("Content-Type", "application/json")
.header("apiKey", "YOUR-API-KEY")
.POST(HttpRequest.BodyPublishers.ofString("{\"name\": \"wikipedia\",\"startUrl\": \"https://en.wikipedia.org/wiki/Main_Page\",\"urlFilter\":{\"segmentNumber\": 1,\"segmentFilter\": [\"wiki\"]}, \"timeout\": 10, \"politeTimeParallelThreads\": 1, \"recrawlTime\": 0, \"keytextOnly\": true, \"maxDocs\": 100}"))
.build();
HttpResponse response = httpClient.send(request,HttpResponse.BodyHandlers.ofString());
System.out.println("Status: "+response.statusCode() + " Response: " +response.body());
Get crawjob (see documentation)
HttpRequest request = HttpRequest.newBuilder()
.GET()
.uri(URI.create("https://server01.seekstorm.com/indices/0/crawljobs/0"))
.header("Cache-Control", "no-cache, no-store")
.header("apiKey", "YOUR-API-KEY")
.build();
HttpResponse response = httpClient.send(request,HttpResponse.BodyHandlers.ofString());
System.out.println("Status: "+response.statusCode() + " Response: " +response.body());
Javascript (Browser and Node.js)
Install and load the node-fetch module
Fetch (Node.js module, Browser native) is a HttpClient. Instalation and loading of the node-fetch module is only required for Node.js, while in browsers fetch is native.
Alternatively also XMLHttpRequest (Node.js module, Browser native), https (Node.js native), request (Node.js module), Axios (Browser library, Node.js module) can be used instead.
//npm install node-fetch
const fetch = require("node-fetch");
Create index (see documentation)
let status;
fetch('https://server01.seekstorm.com/indices', {
method: 'POST',
cache: 'no-cache',
headers: {
'Content-Type': 'application/json' ,
'apiKey': 'YOUR-API-KEY'
},
body: '{"name":"name1","createAutocompleteDictionary":true,"fields":{ "title":{ "store":true,"type":"title"},"content":{ "store":true,"type":"text"},"url":{"store":true,"type":"url"},"domain":{ "store":true,"type":"noindex"},"docDate":{ "store":true,"type":"noindex"}}}'
})
.then((response) => {
status = response.status;
return response.text()
})
.then((body) => {
console.log("Status: "+status+ " Response: "+body);
})
.catch((err) => {
console.error(err);
});
Get index (see documentation)
let status;
fetch('https://server01.seekstorm.com/indices/0', {
method: 'GET',
cache: 'no-cache',
headers: {
'Content-Type': 'application/json' ,
'apiKey': 'YOUR-API-KEY' ,
'Cache-Control': 'no-cache, no-store'
},
})
.then((response) => {
status = response.status;
return response.text()
})
.then((body) => {
console.log("Status: "+status+ " Response: "+body);
})
.catch((err) => {
console.error(err);
});
Index document from string (see documentation)
let status;
fetch('https://server01.seekstorm.com/indices/0/documents', {
method: 'POST',
cache: 'no-cache',
headers: {
'Content-Type': 'application/json' ,
'apiKey': 'YOUR-API-KEY'
},
body: '{"url": "https://en.wikipedia.org/wiki/Encyclopedia", "domain": "en.wikipedia.org", "title": "Encyclopedia - Wikipedia", "content": "An encyclopedia or encyclopaedia (British English) is a reference work or compendium providing summaries of knowledge."}'
})
.then((response) => {
status = response.status;
return response.text()
})
.then((body) => {
console.log("Status: "+status+ " Response: "+body);
})
.catch((err) => {
console.error(err);
});
Get document (see documentation)
let status;
fetch('https://server01.seekstorm.com/indices/0/documents/1', {
method: 'GET',
cache: 'no-cache',
headers: {
'Content-Type': 'application/json' ,
'apiKey': 'YOUR-API-KEY' ,
'Cache-Control': 'no-cache, no-store'
},
})
.then((response) => {
status = response.status;
return response.text()
})
.then((body) => {
console.log("Status: "+status+ " Response: "+body);
})
.catch((err) => {
console.error(err);
});
Query documents (see documentation)
let status;
fetch('https://server01.seekstorm.com/indices/0/documents?'+new URLSearchParams({query: 'wikipedia',offset: 0,length: 10,instant:true,correction:true,completion:true,result:['title','content','url'],summary:'content'}),
{
method: 'GET',
cache: 'no-cache',
headers: {
'Content-Type': 'application/json' ,
'apiKey': 'YOUR-API-KEY' ,
'Cache-Control': 'no-cache, no-store'
},
})
.then((response) => {
status = response.status;
return response.text()
})
.then((body) => {
console.log("Status: "+status+ " Response: "+body);
})
.catch((err) => {
console.error(err);
});
Create crawljob from string (see documentation)
let status;
fetch('https://server01.seekstorm.com/indices/0/crawljobs', {
method: 'POST',
cache: 'no-cache',
headers: {
'Content-Type': 'application/json' ,
'apiKey': 'YOUR-API-KEY'
},
body: '{"name": "wikipedia","startUrl": "https://en.wikipedia.org/wiki/Main_Page","urlFilter":{"segmentNumber": 1,"segmentFilter": ["wiki"]}, "timeout": 10, "politeTimeParallelThreads": 1, "recrawlTime": 0, "keytextOnly": true, "maxDocs": 100}'
})
.then((response) => {
status = response.status;
return response.text()
})
.then((body) => {
console.log("Status: "+status+ " Response: "+body);
})
.catch((err) => {
console.error(err);
});
Get crawjob (see documentation)
let status;
fetch('https://server01.seekstorm.com/indices/0/crawljobs/0', {
method: 'GET',
cache: 'no-cache',
headers: {
'Content-Type': 'application/json' ,
'apiKey': 'YOUR-API-KEY' ,
'Cache-Control': 'no-cache, no-store'
},
})
.then((response) => {
status = response.status;
return response.text()
})
.then((body) => {
console.log("Status: "+status+ " Response: "+body);
})
.catch((err) => {
console.error(err);
});
PHP
Python
Install and import the Requests HTTP library
Requests is a HTTP library.
Alternatively also httplib or urllib can be used instead.
//pip install requests import requests
Create index (see documentation)
url = "https://server01.seekstorm.com/indices"
headers = {"apiKey": "YOUR-API-KEY","Content-Type": "application/json"}
# Python requires True instead of true
json = {"name":"name1","createAutocompleteDictionary":True,"fields":{ "title":{ "store":True,"type":"title"},"content":{ "store":True,"type":"text"},"url":{"store":True,"type":"url"},"domain":{ "store":True,"type":"noindex"},"docDate":{ "store":True,"type":"noindex"}}}
response = requests.post(url, json = json, headers=headers)
print("Status: "+str(response.status_code)+" Response: "+response.text)
Get index (see documentation)
url = "https://server01.seekstorm.com/indices/0"
headers = {"apiKey": "YOUR-API-KEY","Content-Type": "application/json","Cache-Control": "no-cache, no-store"}
response = requests.get(url, headers=headers)
print("Status: "+str(response.status_code)+" Response: "+response.text)
Index document from string (see documentation)
url = "https://server01.seekstorm.com/indices/0/documents"
headers = {"apiKey": "YOUR-API-KEY","Content-Type": "application/json"}
json = {"url": "https://en.wikipedia.org/wiki/Encyclopedia", "domain": "en.wikipedia.org", "title": "Encyclopedia - Wikipedia", "content": "An encyclopedia or encyclopaedia (British English) is a reference work or compendium providing summaries of knowledge."}
response = requests.post(url, json = json, headers=headers)
print("Status: "+str(response.status_code)+" Response: "+response.text)
Get document (see documentation)
url = "https://server01.seekstorm.com/indices/0/documents/1"
headers = {"apiKey": "YOUR-API-KEY","Content-Type": "application/json","Cache-Control": "no-cache, no-store"}
response = requests.get(url, headers=headers)
print("Status: "+str(response.status_code)+" Response: "+response.text)
Query documents (see documentation)
url = "https://server01.seekstorm.com/indices/0/documents"
# Python requires True instead of true
params = {"query": "wikipedia","offset": 0,"length": 10,"instant":True,"correction":True,"completion":True,"result":["title","content","url"],"summary":"content"}
headers = {"apiKey": "YOUR-API-KEY","Content-Type": "application/json","Cache-Control": "no-cache, no-store"}
response = requests.get(url, params=params, headers=headers)
print("Status: "+str(response.status_code)+" Response: "+response.text)
Create crawljob from string (see documentation)
url = "https://server01.seekstorm.com/indices/0/crawljobs"
headers = {"apiKey": "YOUR-API-KEY","Content-Type": "application/json"}
# Python requires True instead of true
json = {"name": "wikipedia","startUrl": "https://en.wikipedia.org/wiki/Main_Page","urlFilter":{"segmentNumber": 1,"segmentFilter": ["wiki"]}, "timeout": 10, "politeTimeParallelThreads": 1, "recrawlTime": 0, "keytextOnly": True, "maxDocs": 100}
response = requests.post(url, json = json, headers=headers)
print("Status: "+str(response.status_code)+" Response: "+response.text)
Get crawjob (see documentation)
url = "https://server01.seekstorm.com/indices/0/crawljobs/0"
headers = {"apiKey": "YOUR-API-KEY","Content-Type": "application/json","Cache-Control": "no-cache, no-store"}
response = requests.get(url, headers=headers)
print("Status: "+str(response.status_code)+" Response: "+response.text)
 Blog
Blog
 Twitter
Twitter
 LinkedIn
LinkedIn