
SymSpell vs. BK-tree: 100x faster fuzzy string search & spell checking
Conventional wisdom and textbooks say BK-trees are especially suited for spelling correction and fuzzy string search. But does this really hold true?
Also in the comments to my blog post on spelling correction the BK-tree has been mentioned as a superior data structure for fuzzy search.
So I decided to compare and benchmark the BK-tree to other options.
Approximate string search algorithms
Approximate string search allows to lookup a string in a list of strings and return those strings which are close according to a specific string metric.
There are are many are different string metrics like Levenshtein, Damerau-Levenshtein, Hamming distance, Jaro-Winkler and Strike a match.
I will compare four different algorithms to lookup a string in a list of strings within a maximum edit distance according to the Damerau-Levenshtein string metric.
For spelling correction an additional word frequency associated with every term can be used to sort and filter the results (suggestions) further.
One could also implement a Weighted Edit distance giving a higher priority to pairs which are close to each other on the keyboard layout or which sound similar (e.g. Soundex or other phonetic algorithms which identify different spellings of the same sound). While there is a SymSpell implementation with weighted Damerau-Levenshtein edit distance / keyboard-distance, the weighted edit distance is beyond the focus of this post. It can be added as a post-processing step with only small impact on the performance to most approximate string searching algorithms by just re-prioritizing/sorting the preliminary results filtered by the Damerau-Levenshtein edit distance according to your preferences.
All algorithms strive for the same goals to achieve short lookup times: reducing the number of lookups and comparisons (between words and/or artificially generated candidates), possibly reducing further the number of full edit distance calculations and finally reducing the computational complexity of the edit distance calculation itself, while not compromising its accuracy.
The four different algorithms I want to compare and benchmark are:
- Norvig’s Spelling Corrector
- BK-tree (Burkhard-Keller-tree)
- SymSpell (Symmetric Delete spelling correction algorithm)
- LinSpell (Linear search spelling correction algorithm)
Levenshtein edit distance variations
All four algorithms are using derivatives of the Levenshtein edit distance. There are three different levenshtein distances:
- Levenshtein distance: adjacent transposition (AC->CA) counted as 2 edits. The triangle inequality does hold.
- Restricted Damerau-Levenshtein distance (Optimal string alignment algorithm): adjacent transposition counted as 1 edit, but substrings can’t be edited more than once: ed(“CA” , “ABC”) =3. The triangle inequality does not hold.
- True Damerau-Levenshtein distance: adjacent transposition counted as 1 edit, substrings can be edited more than once: ed(“CA” , “ABC”) =2. The triangle inequality does hold.
Norvig’s algorithm is using the true Damerau-Levenshtein edit distance. It could be modified to use the Levenshtein distance.
The BK-Tree implementation of Xenopax is using the Levenshtein edit distance. It could be modified to use the True Damerau-Levenshtein edit distance, but not the Restricted Damerau-Levenshtein edit distance where the triangle inequality required for a BK tree does not hold.
SymSpell is using the Restricted Damerau-Levenshtein edit distance. It could be modified to use the Levenshtein distance or the True Damerau-Levenshtein distance.
LinSpell is using the Restricted Damerau-Levenshtein edit distance. It could be modified to use the Levenshtein distance or the True Damerau-Levenshtein distance.
Verbosity of search results
In our tests we distinguish three levels of verbosity of search results, which will result in different lookup times:
Level 0: Return only the result with the smallest edit distance within the maximum edit distance. If multiple results with the same edit distance exist, then return the result with the highest word frequency. This allows for early termination of the search, e.g. if a result with edit distance=0 was found.
Level 1: Return all results with the smallest edit distance within the maximum edit distance. If multiple results with the same edit distance exist, then return them all sorted by word frequency. This allows for early termination of the search, e.g. if a result with edit distance=0 was found.
Level 2: Return all results within the maximum edit distance, sorted by word frequency. This allows for no early termination of the search.
Norvig’s Spelling Corrector
The idea is if we artificially generate all terms within maximum edit distance from the misspelled term, then the correct term must be among them. We have to look all of them up in the dictionary until we have a match. So all possible combinations of the 4 spelling error types (insert, delete, replace and adjacent switch) are generated. This is quite expensive with e.g. 114,324 candidate term generated for a word of length=9 and edit distance=2.
Originally it was written in Python. For the benchmark I used the faithful C# port from Lorenzo Stoakes of Peter Norvig’s algorithm, which has been extended to support edit distance 3.
BK-tree
The BK-tree utilizes the triangle inequality, a property of the Levenshtein edit distance: Levenstein(A,B)+Levenstein(A,C)≥Levenstein(B,C) and Levenstein(A,B)−Levenstein(A,C)≤Levenstein(B,C).
During indexing the Levenshtein(root node,child node) are precalculated.
During lookup we calculate Levenshtein(input ,root node). The [triangle inequality}(https://en.wikipedia.org/wiki/Triangle_inequality) is used as a filter, to only recursively follow those child nodes where the precalculated Levenstein(root node,child node) is in the range [Levenstein(input ,root node)-dmax, Levenstein(input ,root node)+dmax].
There are several interesting posts discussing the BK-tree in detail:
- The BK-Tree — A Data Structure for Spell Checking
- Interesting data structures: the BK-tree
- Interesting data structures: the BK-tree (HN discussion)
- Damn Cool Algorithms Part 1: BK-Trees
- BK-Tree: Introduction & Implementation
- Implementing BK-tree in Clojure
- BK-tree
I compared three C# implementations of the BK-Tree
- BK-Tree1 (C# implementation of tgriffith)
- BK-Tree2 (C# implementation of TarasRoshko)
- BK-Tree3 (C# implementation of Xenopax)
and decided to use the fastest one from Xenopax (which is also linked from Wikipedia) for this benchmark.
SymSpell Algorithm
SymsSpell is an algorithm to find all strings within an maximum edit distance from a huge list of strings in very short time. It can be used for spelling correction and fuzzy string search.
SymSpell derives its speed from the Symmetric Delete spelling correction algorithm and keeps its memory requirement in check by prefix indexing.
The Symmetric Delete spelling correction algorithm reduces the complexity of edit candidate generation and dictionary lookup for a given Damerau-Levenshtein distance. It is six orders of magnitude faster (than the standard approach with deletes + transposes + replaces + inserts) and language independent.
Opposite to other algorithms only deletes are required, no transposes + replaces + inserts. Transposes + replaces + inserts of the input term are transformed into deletes of the dictionary term. Replaces and inserts are expensive and language dependent: e.g. Chinese has 70,000 Unicode Han characters!
The speed comes from inexpensive delete-only edit candidate generation and pre-calculation. An average 5 letter word has about 3 million possible spelling errors within a maximum edit distance of 3, but SymSpell needs to generate only 25 deletes to cover them all, both at pre-calculation and at lookup time. Magic!
The idea behind prefix indexing is that the discriminatory power of additional chars is decreasing with word length. Thus by restricting the delete candidate generation to the prefix, we can save space, without sacrificing filter efficiency too much. In the benchmark three different prefix lengths lp=5, lp=6 and lp=7 were used. They reflect different compromises between search speed and index size. Longer prefix length means higher search speed at the cost of higher index size.
The C# source code of SymSpell is released as Open Source on GitHub.
The Rust source code of SymSpell is released as Open Source on GitHub.
LinSpell
This is basically a linear scan through the word list and calculating the edit distance for every single word (with a few tweaks). It was intended as the baseline measure for the benchmark. Surprisingly enough and despite its O(n) characteristics it turned out to excel both BK-tree and Norvig’s algorithm.
There are several reasons for that:
- do not underestimate the constants in the Big O notation. Visiting only 20% of the nodes in a BK-tree is more expensive than a linear search where the atomic cost is only 10%.
- As Damerau-Levenshtein calculation is very expensive it is not the number of processed words which matters, but the number of words where we need the full Damerau-Levenshtein calculation. We can speedup the search if we can prefilter words from the calculation or terminate the calculation once a certain edit distance is reached.
- If we restrict the search to best match we can utilize options for early termination of the search.
- words with no spelling errors are a frequent case. Then the lookup can be done with a hash table or trie in O(1) ! If we restrict the search to best match, we can instantaneously terminate the search.
- We do not need to calculate the edit distance if Abs(word.Length-input.Length) > Maximum edit distance (or best edit distance found so far if we restrict the search to best match)
- If we restrict the search to best match, we can terminate the edit distance calculation once the best edit distance found so far is reached.
- If we restrict the search to best match, and we have found already one match with edit distance=1, then we do not need to calculate the edit distance if the count of the term in question is smaller than the count of the match already found.
The C# source code of LinSpell is released as Open Source on GitHub.
Test setup
In order to benchmark the four approximate string searching algorithms we perform 2/3/3+2/*2 tests for each algorithm:
1000 words with random spelling errors are searched for two dictionary sizes (29,159 words, 500,000 words), three maximum edit distances (2, 3, 4) and three verbosity types (0, 1, 2). For each test the total search time is measured.
For two dictionary sizes (29,159 words, 500,000 words) the precalculation time necessary to create the dictionary and auxiliary data structures and their memory consumption are measured.
For each of the four algorithms the found suggestions have been compared to ensure completeness of results. Result differences caused by the different Levenshtein variations used by the algorithms have been taken into account.
Test focus & limitations
The benchmark has been limited to maximum edit distance up to 4, because for natural language search an edit distance of 4 is already on the border of what’s reasonable, as the number of false positives grows exponentially with the maximum edit distance, decreasing precision, while improving recall only slightly.
The benchmark has been limited to a dictionary size up to 500,000 words because even the 20-volume Oxford English Dictionary contains only 171,476 words in current use, and 47,156 obsolete words.
Fuzzy search beyond natural language search with longer strings or bit vectors (images, voice, audio, video, DNA sequences, fingerprints, …) may require higher edit distances and larger dictionary sizes and lead to different results.
Fuzzy search for multiple words (product/event databases) or larger text fragments (plagiarism check) will likely require compounding/decompounding and string metrics beyond edit distances like Strike a match to account for missing and switched words.
Both application fields are beyond the focus of this post.
Test data
noisy_query_en_1000.txt
For the query we use the first 1000 unique words. from Norvig’s text corpus big.txt.
For each word a random number of edits in the range 0..Min(word.length/2 , 4) is chosen. For each edit a random type of edit (delete, insert random char, replace with random char, switch adjacent chars) is applied at a random position within the word. After the edits no duplicates and words with length<2 are allowed.
frequency_dictionary_en_30_000.txt
These are the 29,159 unique words from Norvig’s text corpus big.txt, together with their frequency in that corpus. frequency_dictionary_en_500_000.txt
These are the most frequent 500,000 words from the English One Million list from Google Books Ngram data, together with their frequency.
All three test data files are released on GitHub.
If you want to reproduce the benchmark results yourself or compare to another fuzzy string search algorithm, you will find the benchmark source code on Github too.
Benchmark results


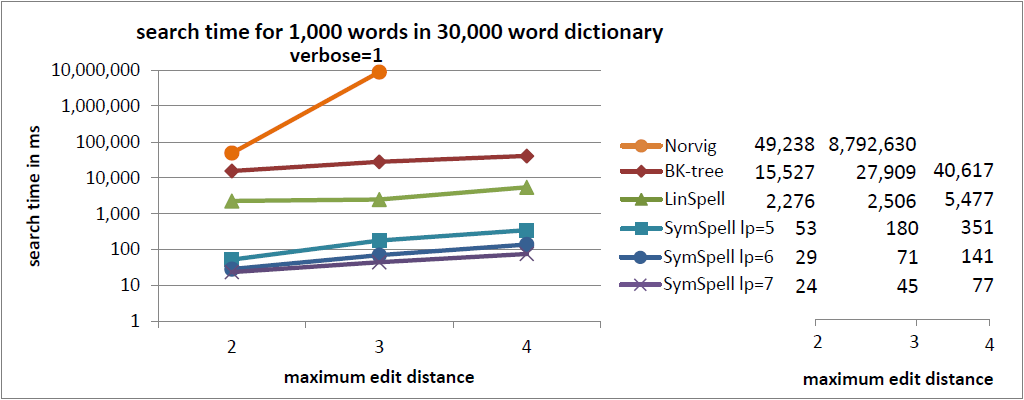
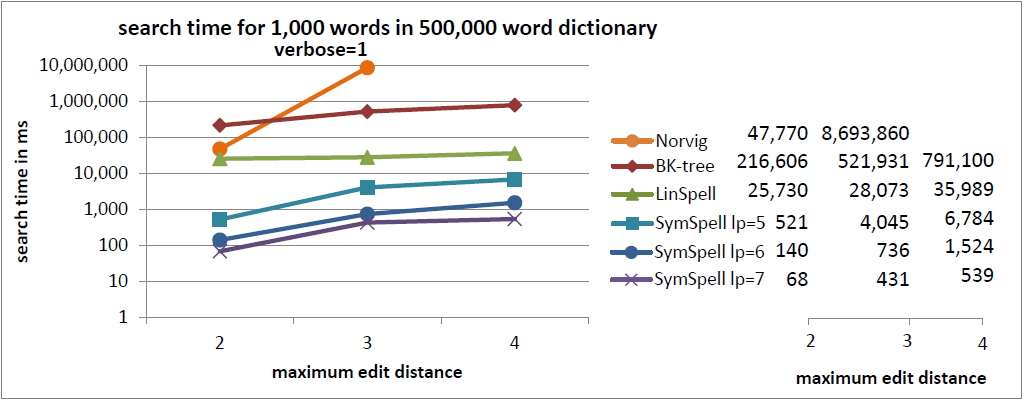
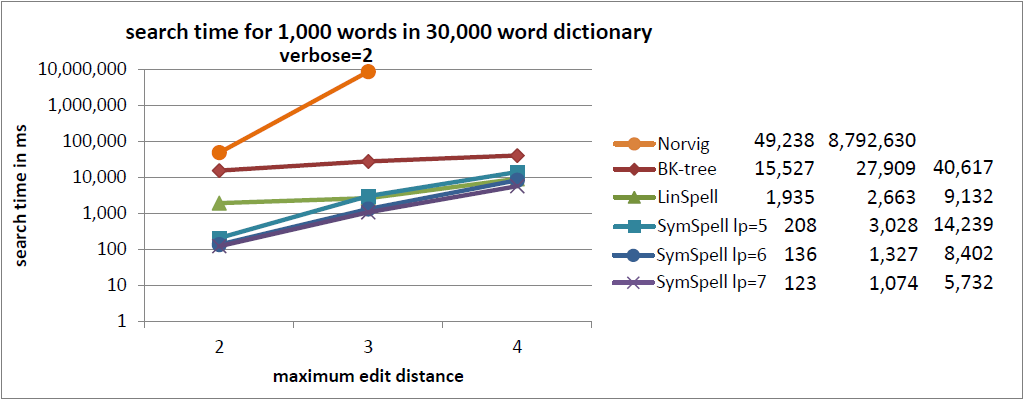
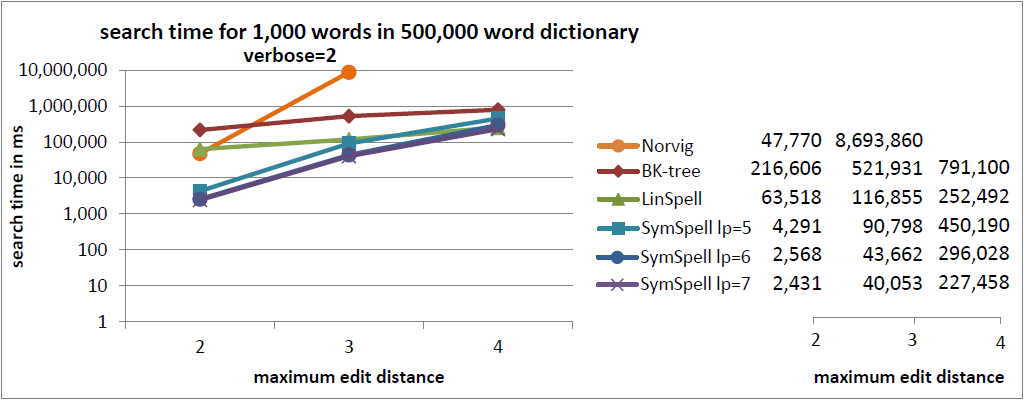
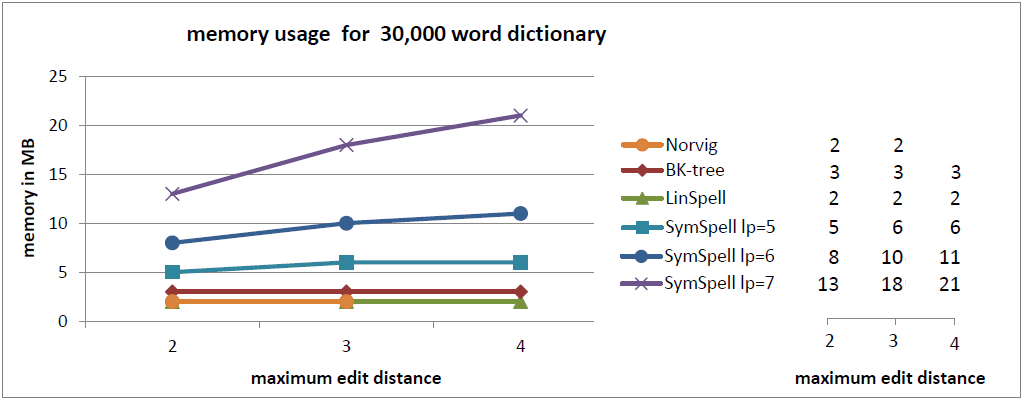
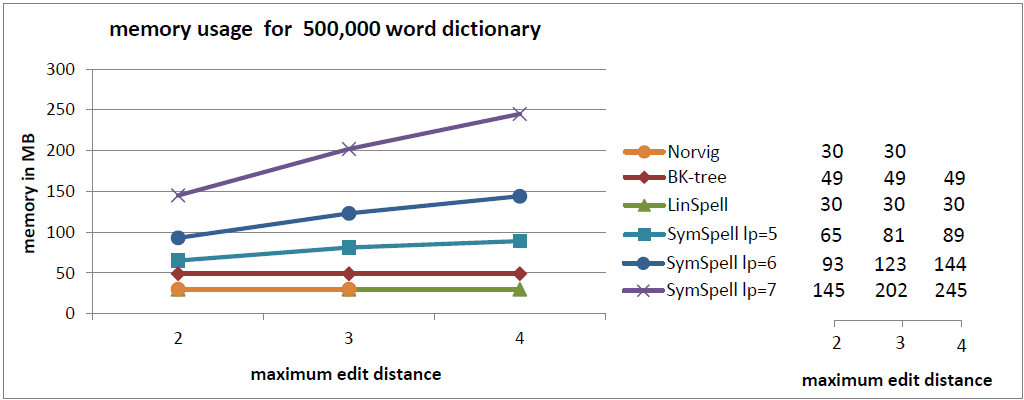
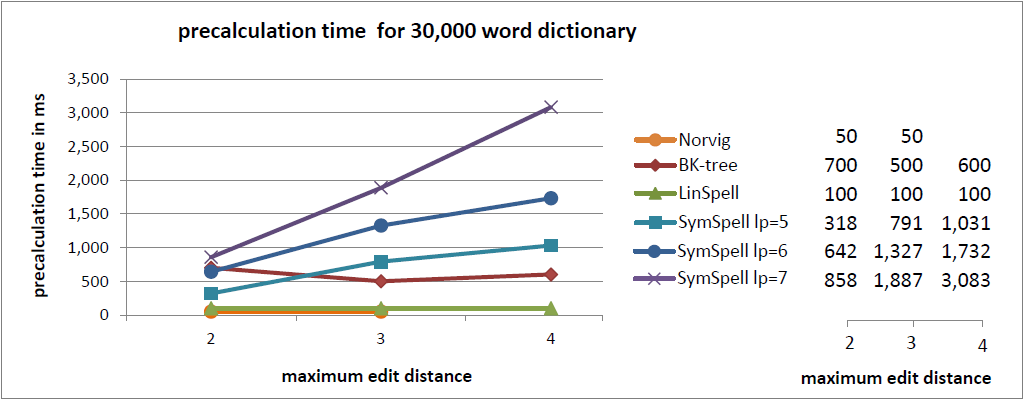
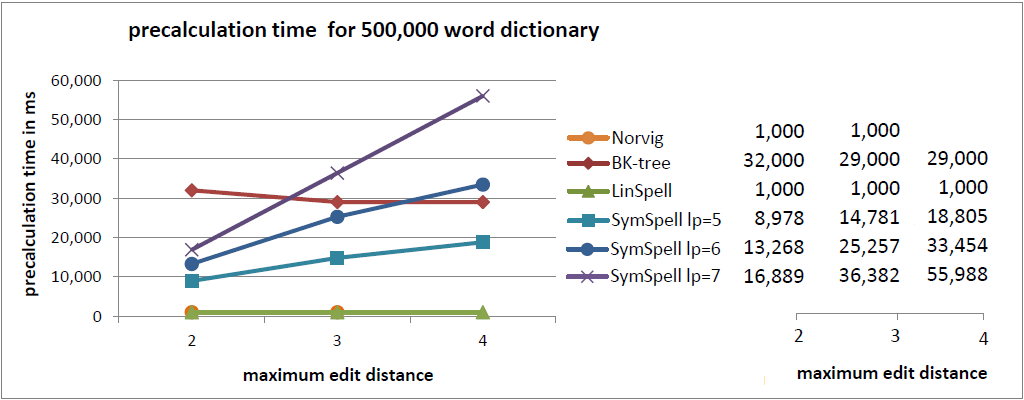
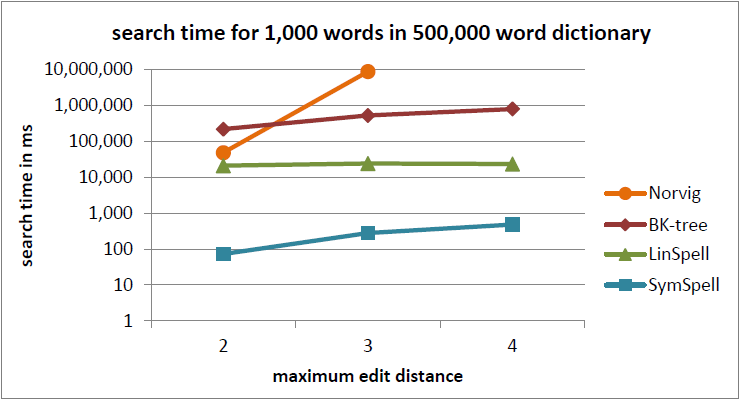
In the current benchmark we compared words with a random edit distance (0…maximum edit distance). This gives a good understanding of the average lookup time.
In a previous benchmark we were comparing words with a fixed edit distance (= maximum edit distance). This gives a good understanding of the maximum lookup time. ]Sometimes averages can be misleading](https://www.elastic.co/blog/averages-can-dangerous-use-percentile) as measure for user experience. For edit distance=3 SymSpell was 1 million times faster than Norvig’s algorithm.
Application
SymSpell is very fast. But do we really need that speed and what for? For a single user or for small edit distances other algorithms might just be fine. But for search engines and search as a service search API where you have to serve thousands of concurrent users, while still maintaining a latency of a few milliseconds, and where spelling correction is not even the main processing task, but only one of many components in query preprocessing, you need the fastest spelling correction you can get.
Summary
The benchmark could not confirm any rationale behind the widespread use and recommendation of BK-trees and Norvig’s algorithm other than historical reasons and habit that is perpetually passed on by text books and forums. With SymSpell and LinSpell there are two alternative algorithms available which always provide better results, at least within the scope of this test.
- Use SymSpell, if speed is important. It is 2–3 orders of magnitude faster than BK-Tree and 5–6 orders of magnitude faster than Norvig’s algorithm. SymSpell lookup time grows only moderate with dictionary size and maximum edit distance. It outperforms all other three algorithms in all cases, often by several orders of magnitude. This comes at the cost of higher memory consumption and precalculation times. Precalculation times incur only once during program/server start or even only during program development if the precalculated data is serialized/deserialized.
- Use LinSpell, if memory usage is important. It is 10* faster than BK-Tree for same memory usage. LinSpell lookup time grows linearly with the size of the dictionary, but is nearly independent from the maximum edit distance. It is almost always better than BK-tree and Norvig’s algorithm. No additional memory consumption and precalculation times incur.
- There is no obvious benefit of using a BK-tree. In all cases it is excelled speedwise by SymSpell and both speed & memory wise by LinSpell. While a BK-tree is faster than Norvig’s algorithm for edit distance>2, it is much slower than LinSpell or SymSpell. BK-tree performance depends heavily on the size of the dictionary, but grows only moderate with maximum edit distance.
- There is no obvious benefit of Norvig’s algorithm. In all cases it is excelled speedwise by SymSpell and LinSpell and matched memory wise by LinSpell. Lookup time of Norvig’s algorithm is independent from the size of the dictionary, but grows exponentially with maximum edit distance.
- Always use verbose=2 carefully (enumerate all suggestion within maximum edit distance, not only those with the smallest edit distance). It is much slower, as it prevents an early termination of the search!
Update:
I received an email which expressed some skepticism about the benchmark results and suggested that the outcome was due to the poor C# implementation of the chosen BK-tree rather than the algorithmic differences between BK-tree and SymSpell. I thought I had been already extra careful to prevent such suspicion by selecting the fastest BK-tree implementation in C# I could find. But admittedly, sometimes it might indeed be difficult to distinguish to which percentage the algorithm or its implementation contribute to the performance.
I will add some objective data: the average number of Levenshtein calculations done during a search in a dictionary:
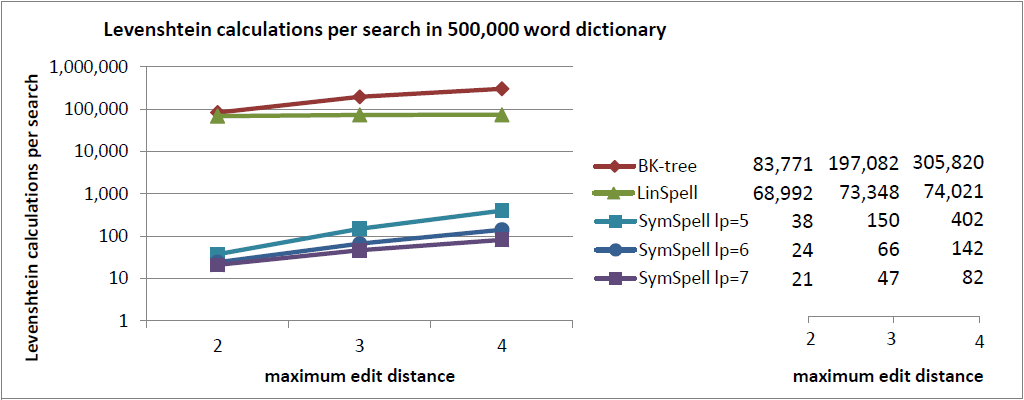
As the Levenshtein calculations are the most expensive component of a search both in BK-tree and in SymSpell, the average number of Levenshtein calculations required during a search in a dictionary of a given size should be a fairly incorruptible indicator of the true performance of the algorithm, independent from its implementation.
While for the BK-Tree we need to calculate the Levenshtein distance for 17% to 61% of the vocabulary (words in the dictionary), SymSpell has to calculate the Levenshtein distance only for 0.0042% to 0.016% of the vocabulary. That’s why SymSpell’s speed has its origins in the design of the algorithm, and not in the implementation.
Btw, I also tested an integration of the BK-tree triangle inequality principle into SymSpell as an additional step to further reduce/filter the number of required Levenshtein calculations. There were only little performance improvements, but increased memory requirement and precalculation costs due to Levenshtein calculations during dictionary generation.