
SeekStorm is now Open Source
SeekStorm sub-millisecond full-text search (Rust) is now Open Source
SeekStorm is an open source, sub-millisecond full-text search library & multi-tenancy server implemented in Rust.
Porting from C# to Rust - why?
Porting the SeekStorm codebase from C# to Rust
- Factor 2..4x performance gain (latency and throughput)
- No slow first run (no cold start costs due to just-in-time compilation)
- Stable latencies (no garbage collection delays)
- Less memory consumption (no ramping up until the next garbage collection)
- Steep learning curve (previously development time divided between designing algorithms and debugging, now between translating and fighting with the compiler borrow checker)
Rust is great for performance-critical applications 🚀 that deal with big data and/or many concurrent users. Fast algorithms will shine even more with a performance-conscious programming language 🙂
But we didn’t stop at faithfully porting all the code from C# to Rust. It has been a redesign of architecture and algorithms, incorporating everything we learned from 4 years of operating SeekStorm in production as a multi-tenancy search-as-a-service.
Why another search library? Performance and scalability without the cost.
Despite what the hype cycles want you to believe, Keyword search is here to stay, right beside vector search and LLMs.
Keyword/Lexical search is such a basic/fundamental technology, that has countless application fields and still excels in many areas due to its simplicity, universality, and performance. But even a mature technology like keyword search which has been there for decades, is still open to innovation in architecture and algorithms that enable performance improvements by an order of magnitude to make it fit for the next decades to come.
The amount of data produced is growing exponentially, and more and more applications rely on processing those data at a massive scale, without sacrificing performance. The scalability of your search infrastructure has to keep up. Sure, you can always add more servers, shards, and replicas. This increases the complexity, cost, and energy consumption. But like LED technology can produce the same amount of light as incandescent bulbs with much less energy and cost, technology can achieve the same efficiency leap for search.
Why search performance is so important
- Search speed might be good enough for a single search. Below <10 ms people can’t tell latency anymore. Also, search latency might be small compared to Internet network latency.
- But search engine performance still matters when used in a server or service for many concurrent users and requests for maximum scaling, and throughput, and low processor load, cost.
- With performant search technology you can serve many concurrent users, at low latency with fewer servers, less cost, and less energy consumption, lower carbon footprint.
- It also ensures low latency even for complex and challenging queries: instant search, fuzzy search, faceted search, and union/intersection/phrase of very frequent terms.
- Besides average latencies we also need to reduce tail latencies, which are often overlooked, but can cause a loss of customers, and revenue and can lead to a bad user experience.
- It is always advisable to engineer your search infrastructure with enough performance headroom, to keep those tail latencies in check, even on periods or spikes of high concurrent load.
- Also, even if a human user might not notice the latency, it still might make a big difference in autonomous stock markets or defense applications or RAG which requires multiple queries.
Open source
The Rust port of the SeekStorm sub-millisecond full-text search library and multi-tenancy server is open-sourced under Apache License 2.0 and available on GitHub.
The SeekStorm port to Rust is our fourth and largest open-source project after SymSpell, PruningRadixTrie, and WordSegmentationTM. All four projects have been performance-oriented and pushed the boundaries of the previous state-of-the-art by quite a bit.
With a combined 3,500 stars on Github, all projects have been quite popular, and we hope you will like our search solution as well, whether as a hosted service or an open-source library.
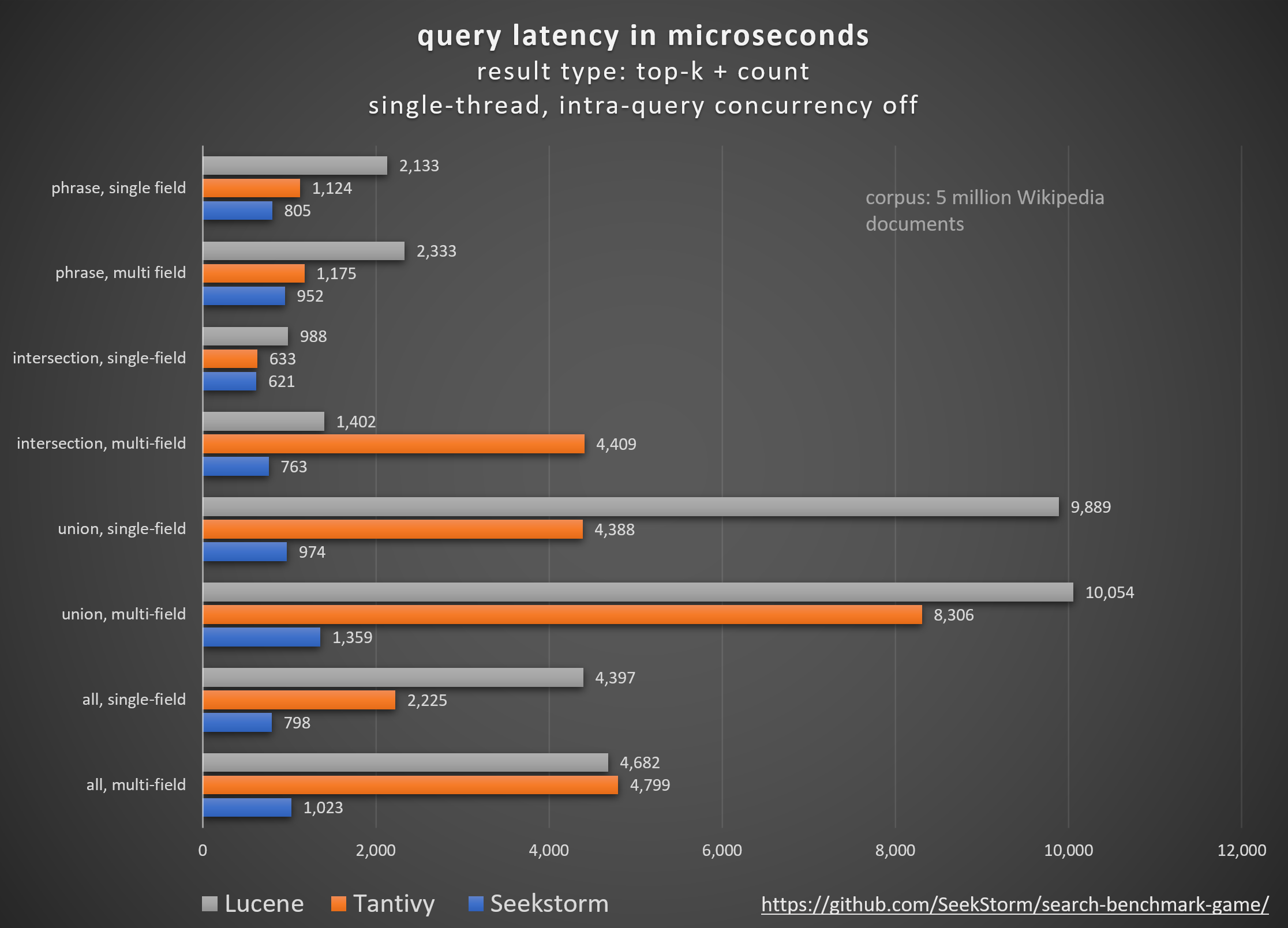
Benchmarks
The first benchmarks of the Rust port of the SeekStorm sub-millisecond full-text search library and multi-tenancy server are in. Still preliminary, currently porting intra-query concurrency, LSM-trie, faceted search and updating documentation.
Open-source search engine libraries (BM25 lexical search) are compared using the open-source search_benchmark_game developed by Tantivy and Jason Wolfe.
Indexing test data: The benchmark is based on the English Wikipedia corpus (5,032,105 documents, 8,28 GB decompressed).
wiki-articles.json has a .JSON extension, but it is not a valid JSON file. It is a text file, where every line contains a JSON object with url, title and body attributes. The format is called ndjson, also referred to as “Newline delimited JSON”.
Query test data: the benchmark uses queries derived from the AOL query dataset
Hardware: Thinkpad P1, 64,0 GB RAM, Intel Core i7-13700H 2.40 GHz, 2TB Hynix NVMe SSD
Multi-field search
Multi-field search at almost no performance cost is desirable, but can’t be taken for granted with every search library.
While some benchmarks focus solely on search within a single field, those results are not very representative of real-world use cases. In most cases, we need to search through multiple fields at the same time. How much this influences the performance, namely latency and throughput, highly depends on the used data structures and algorithms of the search library.
Often, the number of terms in the (e.g.) title field is negligible compared to the (e.g.) body field, yet searching through both fields can be expensive in some search libraries.
Btw., concatenating both fields before indexing is not a viable solution because it prohibits BM25F scoring, where matches in a shorter title field should receive a higher score.
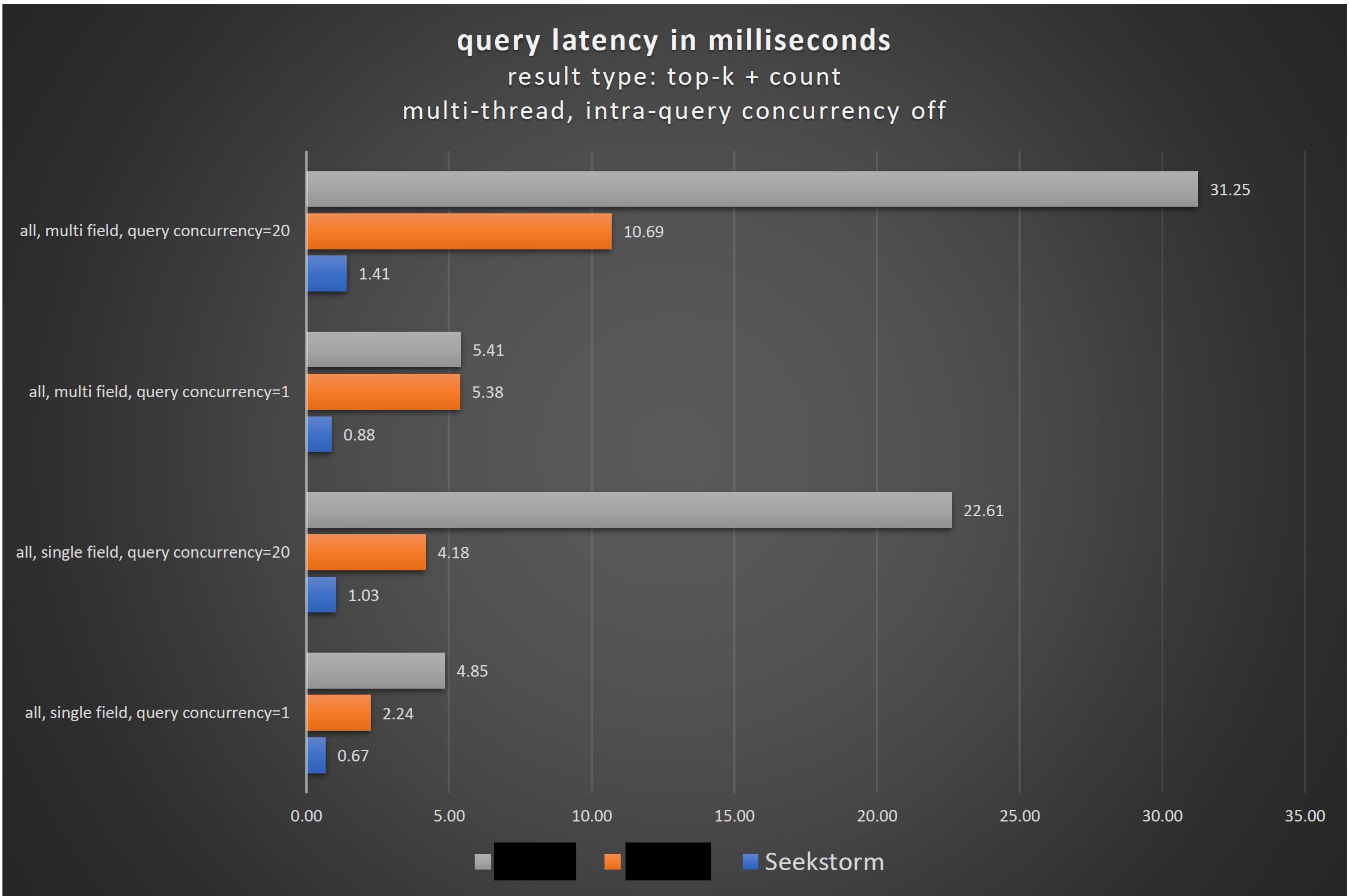
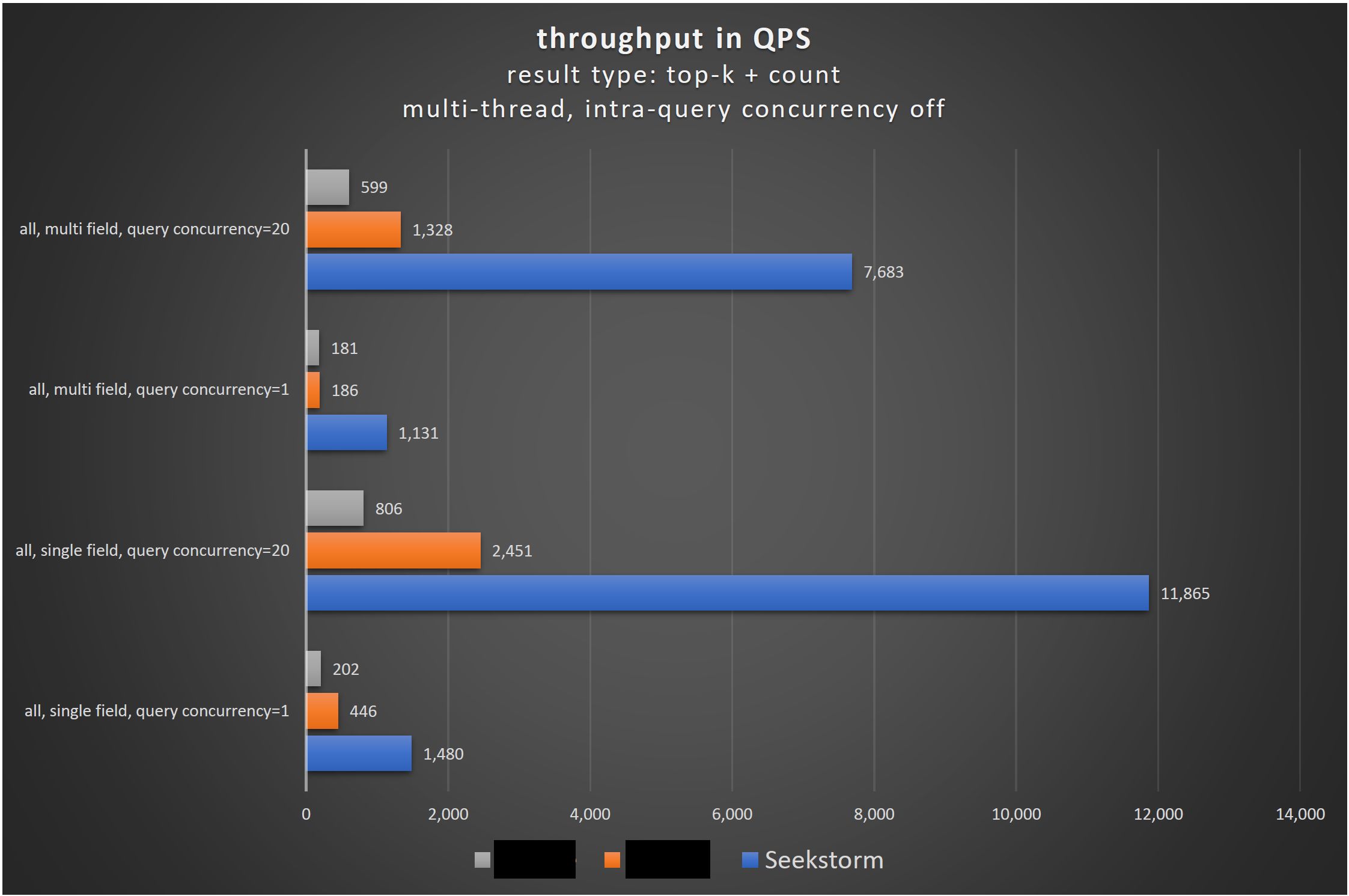
Concurrent queries: the standard use case
While most search benchmarks still focus on single-field, single-user tests the much more realistic real-world use case is a multi-field index, with concurrent queries. Unless you have a local single-user installation on your notebook you will usually have many concurrent users accessing your server. Not only is this the most frequent use case, but it allows also you to test whether your architecture utilizes and saturates all processor cores for increased throughput and low latency. If that’s the main use case then we should also benchmark exactly this scenario and make technology decisions based on those results.
Relevancy
Many search libraries still use Okapi BM25 as the default ranking function, though it doesn’t work well for phrase search, as it doesn’t consider the proximity and order of query terms.
Sure, you can select a different scorer or customize it, but why force your users to do a deep dive into documentation, and information retrieval, and reinvent, what should have been the default in the first place?
Also, why would you force your users to formulate an explicit phrase search with “” just to get a phrase-aware scoring (not filtering)? Phrase-aware ranking should be the default, whether or not the user is explicitly using “”.
Wouldn’t it be better to assist the user on every step, and make search as painless and successful as possible, even without being an expert?
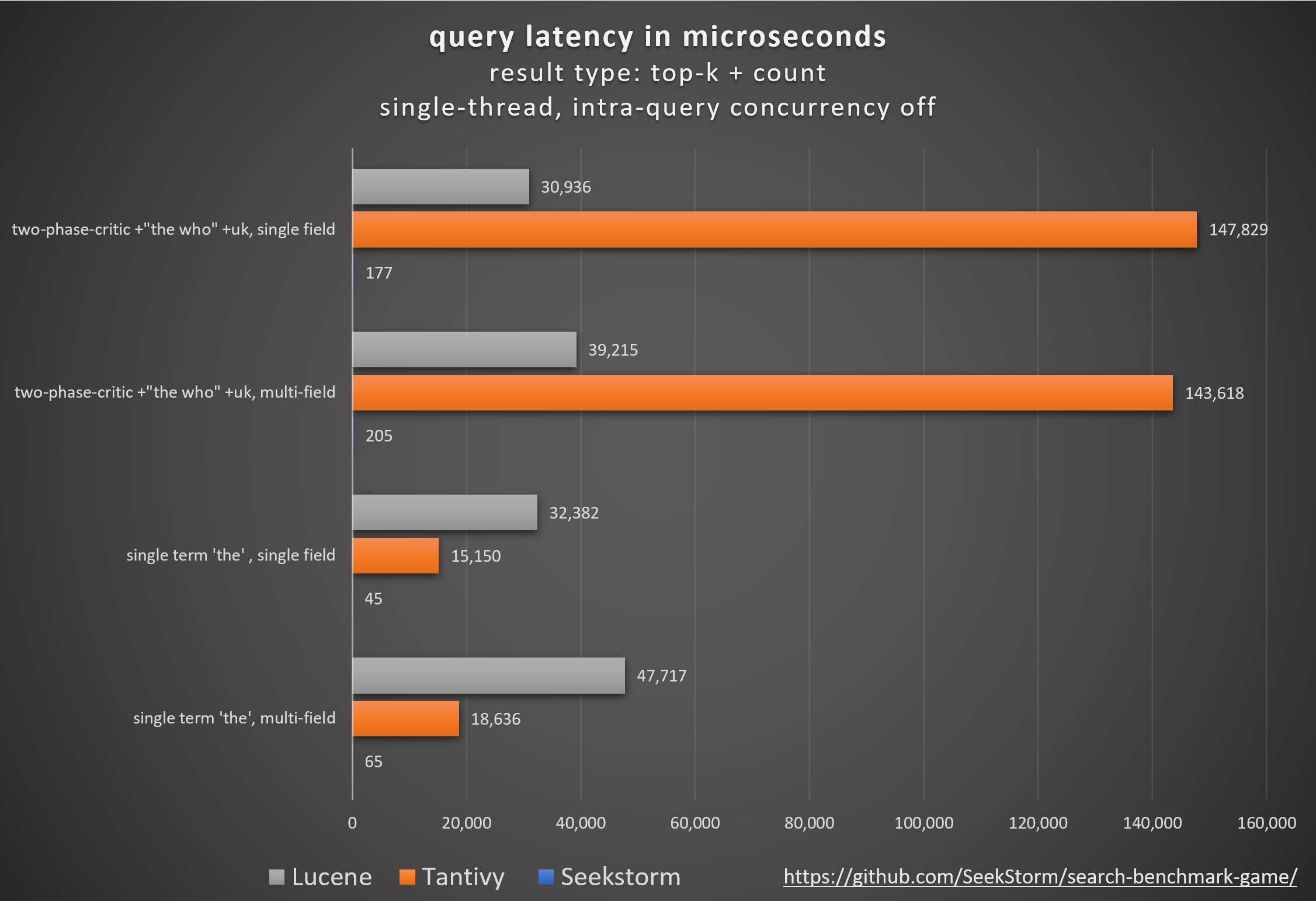
Query: the who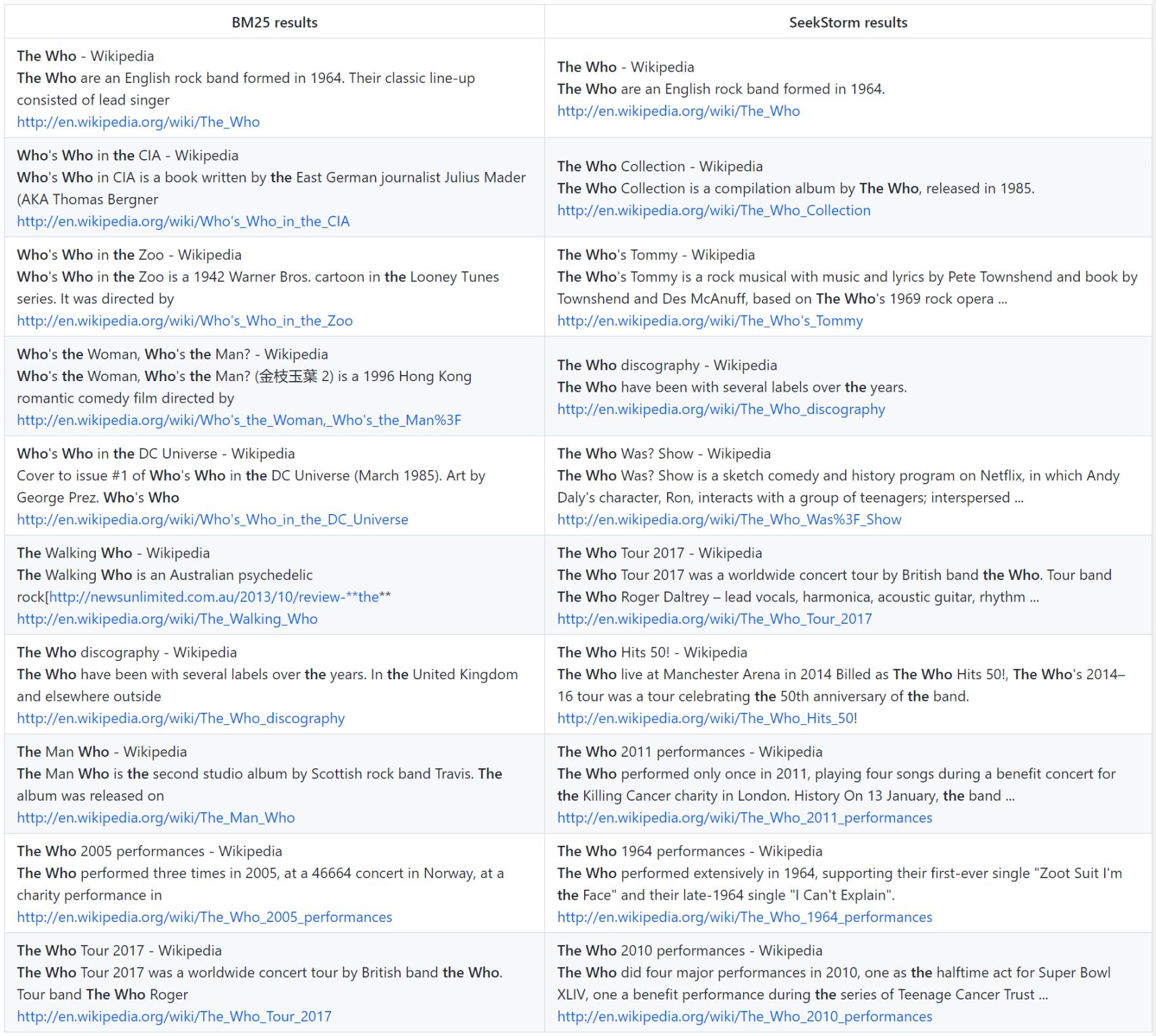
Key contributions
SeekStorm significantly improves the query performance compared to the current state of the art in the following areas:
| query type | number of searched fields (title+body vs. body) | concurrent queries | factor vs. Tantivy | factor vs. Lucene |
|---|---|---|---|---|
| all | 2 | 1 | 4.7x | 4.6x |
| all | 1 | 1 | 2.8x | 5.5x |
| union | 2 | 1 | 6.1x | 7.4x |
| union | 1 | 1 | 4.5x | 10.1x |
| intersection | 2 | 1 | 5.8x | 1.8x |
| intersection | 1 | 1 | 1x | 1.6x |
| single frequent term (‘the’) | 2 | 1 | 286.7x | 734.1x |
| single frequent term (‘the’) | 1 | 1 | 336.7x | 719.6x |
| two-phase-critic (+”the who” +uk) | 2 | 1 | 700.6x | 191.3x |
| two-phase-critic (+”the who” +uk) | 1 | 1 | 835.2x | 174.8x |
Keyword search is here to stay, right beside vector search and LLMs
Despite what the hype-cycles want you to believe, keyword search is not dead or outdated, as NoSql wasn’t the death of Sql, and bloom filters didn’t make hashsets obsolete.
We all share the excitement whenever a new technology surfaces, that offers radical new capabilities.
But those are all just tools in a toolbox, where there is no one-fits-all tool. Time-proven doesn’t mean outdated.
Sure, new technologies will take over in some areas where they are better suited. And then there is some overlap in application fields, where either of the tools might have an advantage, depending on what your exact requirements are: performance, exactness, completeness, grasp of meaning and synonyms, zero-shot, out-of-vocabulary, and real-time capabilities.
But the more basic/fundamental a technology is, the more likely it is there to stay and still excel in many areas due to its simplicity, universality, and performance.
At its core, keyword search is just a filter for a set of documents, returning those where certain keywords occur, usually combined with a ranking metric like BM25. A very basic and core functionality, that is very challenging to implement at scale with low latency. Because the functionality is so basic, there is an unlimited number of application fields. It is a component, to be used together with other components. There are use cases that can be solved better today with vector search and LLMs, sometimes combining keyword search and vector search into hybrid search exceeds each of them, but in many instances keyword search is still the best solution.
Keyword search is exact, lossless, works with any language, with new, out-of-vocabulary terms, is always up-to-date, doesn’t require huge existing corpora for expensive and time-consuming learning of embeddings or LLMs which are prone to become outdated, it is very fast, with better scaling, better latency, and throughput, has much less infrastructure requirements, and consequently, is much more energy-efficient.
You should know all your tools, and what their benefits and drawbacks are for your specific use case. Most of the time, technologies are not competing, but complementing each other. Maintain a toolbox, and choose the best tool for your task at hand. https://seekstorm.com/blog/vector-search-vs-keyword-search1/
Even today, with a mature technology like keyword search which has been there for decades, innovation in architecture and algorithms enables performance improvements by a order of magnitude and make it fit for the next decades to come.
Keyword search is here to stay, and whenever performance is important, SeekStorm might be one of the best options for you.