
Elias-Fano: quasi-succinct compression of sorted integers in C#

Photo by Matt Artz
Introduction
This post explores the Elias-Fano encoding, which allows as a very efficient compression of sorted lists of integers, in the context of Information retrieval (IR).
Elias-Fano encoding is quasi succinct, which means it is almost as good as thebest theoretical possible compression scheme for sorted integers. While it can be used to compress any sorted list of integers, we will use it for compressing posting lists of inverted indexes.
While gap compression has been around for over 30 years, and some of the foundations of Elias-Fano encoding even date back to a 1972 publication by Peter Elias, Elias Fano encoding itself has been published in 2012. Being a rather recent development beyond the papers there is not much actual implementation code available. That’s why I want to contribute my implementation of that beautiful and efficient algorithm as Open Source.
Elias-Fano compression uses delta coding, also known as gap compression. It is an invertible transformation that maps large absolute integers to smaller integers of gaps/deltas, that require less bits. The list of integers is sorted and then the delta values (gaps) between two consecutive values are calculated. As the deltas are always smaller than the absolute values we can encode them with fewer bits and thus achieve a compression (this is true for any delta compression).
Elias-Fano as any gap compression requires the lists to be sorted. Therefore it is applicable only when the original order of elements is without meaning and can be lost.
Elias-Fano encodes the gaps within the average distance with fewer bits than the rare outliers above, by splitting the encoding of a gap in low bits and high bits:
- The low bits l= log(u/n) are stored explicitly.
- The remaining high bits are stored in unary coding
This requires at most 2 + log(u/n) bits per element and is quasi succinct with less than half a bit away from the succinct bound!
Inverted index and posting lists
While Elias-Fano encoding can be used to compress any sorted list of integers, a typical application in Information Retrieval is compressing posting lists of inverted indexes as core of a search engine. Hence here comes a short recap of both posting lists and inverted indexes:
An Inverted Index is the central data structure of most information retrieval systems and search engines. It maps terms of a vocabulary V to their locations of occurrences in a collection of documents:
- A dictionary maps each term of the vocabulary to a separate posting list.
- A posting list is a list of the document ids (DocID) of all documents where the term appears in the text.
A document id is the index number of an document within a directory of all documents. A document id is usually represented by an integer, hence posting list are lists of integers. A 32 bit unsigned integer allows the addressing of 4,294,967,296 (4 billion) documents, while an 64 bit unsigned integer allows the addressing of 18,446,744,073,709,551,616 (18 quintillion) documents.
Of course we could use a posting list with URLs instead of DocIDs. But URLs (77 byte average) take much more memory than DocIDs (4 or 8 byte), and a document is referred to from all posting lists of the terms (300 terms/document average) contained within the document text. For 1 billion pages it would be 300 * 77byte * 1 billion = 23 TB for posting lists of DocID vs. (77+300 * 4) * 1 billion= 1277 GB for posting lists of URL, which is a factor of 18.
Index time and retrieval time
At index time the inverted index is created. After a crawler fetches the documents (web pages) from the web, they are parsed into single terms (any HTML markup is stripped). Duplicate terms are removed (unless you create an positional index where the position of every occurrence of a word within a page is stored). During this step also the term frequency (number off occurrences of a term within a document) can be counted for TF/IDF ranking.
For each term of a document the document id is inserted into the posting list of that term. Static inverted indexes are built once (e.g. with MapReduce) and never updated. Dynamic inverted indexes can be updated incrementally in real time or in batches (e.g. with MapReduce).
At search time for each term contained in the query the corresponding posting list is retrieved from the inverted index.
Boolean queries are performed by intersecting the posting lists of multiple terms, so that only those DocID are added to the result list which occur an all of the posting lists (AND) or in any of the posting lists (OR)
Performance and scaling
Implementing an inverted index seems pretty straight forward. But when it comes to billions of documents, an index which has to be updated in real time, and queries of many concurrent users that require very low response times we have to give more thought on the data structures and implementation.
Low memory consumption and fast response time are key performance indicators of inverted indexes and information retrieval systems (the latter with additional KPI as precision, recall and ranking). Posting list are responsible for most of the memory consumption in an inverted index (apart from than the storage of the documents itself). Therefore the reduction of the memory consumption of posting lists is paramount. Some believe that Index compression is one of the main differences between a “toy” indexer and one that works on real-world collections.
Posting list compression
This can be achieved by different posting list compression algorithms. All of the compression algorithms listed below use an invertible transformation that maps large integers of the DocIDs to smaller integers, that require less bits.
Posting list compression reduces the size, thus either less memory is required for a certain number of documents or more documents can be indexed in a certain amount of memory. Also, by reducing the size of a posting list, storing and accessing the posting list in much faster RAM becomes feasible instead storing and retrieving the posting list from slower hard disk or SSD. This leads to faster indexing and query response times.
Posting list compression comes with a cost of additional compression time (index time) and decompression time (query time). For performance comparison of different compression algorithms and implementations always the triple of compression ratio, compression time and decompression time should be considered.
For efficient query processing and intersection (with techniques as skipping) the compression algorithm should support direct access with only partial decompression of the posting list.
Posting list compression algorithms
bitstuffing/bitpacking
Instead of being fixed-size (32 or 64 bits per value), integer values can have any size. The number of bits per DocID is chosen as small as possible, but so that the largest DocID can be still encoded. Storing 17-bits integers with bitpacking achieves a 47% reduction compared to an unsigned 32 bit integer! There is a speed penalty when the number of bits per DocID is no multiple of 8 and therefore byte borders are crossed.
binary packing/frame of reference (FOR)
Similar to bitpacking, but the posting list is partitioned into smaller blocks first. Then each block is compressed separately. Adapting the number of bits to the range of each block individually allows a more effective compression, but comes at the cost of increased overhead as minimum value, length of block, and number of bits/DocID need to be stored for each block.
Patched frame of reference (PFOR)
Similar to frame of reference, but within a block those DocIDs are identified which as outliers unnecessary expand the value range, leading to more bits/DocID and thus prevent an effective compression. Outlier DocIDs are then separately encoded.
delta coding / gap compression
The DocID of the posting list are sorted and then the delta values (gaps) between two consecutive DocIDs are calculated. As the deltas are always smaller than the absolute values we can encode them with fewer bits and thus achieve a compression.
- elias gamma coding
- elias delta coding
- elias omega coding
- golomb/rice coding
- simple-8b, simple-9, simple-16
- variable byte coding
- elias fano coding
Elias-Fano coding
The most efficient of the Elias compression family, and quasi succinct, which means it is almost as good as the best theoretical possible compression scheme. It can still be further improved by splitting the posting list into blocks and compressing them individually (partitioned Elias-Fano coding).
It compresses gaps of sorted integers (DocIDs): Given n (number of DocIDs) and u (maximum DocID value = number of indexed docs) we have a monotone sequence 0 = x0, x1, x2, … , xn-1 = u, with strictly monotone/increasing DocIDs, no duplicate DocIDs allowed and strictly positive deltas, no zero allowed.
Elias-Fano encodes the gaps within the average distance with fewer bits than the rare outliers above, by splitting the encoding of a gap in low bits and high bits:
- The low bits l= log(u/n) are stored explicitly.
- The remaining high bits are stored in unary coding
This requires at most 2 + log(u/n) bits per element and is quasi succinct with less than half a bit away from the succinct bound! The compression ratio depends highly (and solely) on the average delta between DocIDs/items (delta = gap = value range/number of values = number of indexed docs/posting list length):
- 1 billion docs/10 million DocIDs = 100 (delta) = 8,6 bit/DocID max (8,38 real)
- 1 billion docs/100 million DocID =10 (delta) = 5,3 bit/DocID max (4,76 real)
Papers:
Implementation specifics
Because the algorithm itself is quite straightforward, but used for huge posting lists, the optimization potential lay in a careful implementation rather than in optimizing the algorithm itself.
Reusing predefined arrays instead of dynamically creating and increasing Lists, preventing if/then branches to allow efficient processor caching, using basic types instead of objects, plain variables instead indexed array cells and generally shaving the cost of every single operation.
Algorithm-wise a translation table is used to decode/decompress the high bits of up to 8 DocIDs which may be contained within a single byte in parallel.
Posting List Compression Benchmark
The benchmark evaluates how well the Elias-Fano algorithm and our implementation perform for different posting list sizes, number of indexed documents and average delta in respect to the key performance indicators (KPI) compression ratio, compression time and decompression time.
We are using synthetic data for the following reasons: even for web scale Big Data they are easy and fast to obtain and exchange without legal restrictions, their properties are easier to understand and to adapt to specific requirements, they don’t need to be stored but can be recreated on demand or on the fly. As the creation of massive test data is often faster than loading from disk, this less influences the benchmark. Creation on the fly makes huge test sets possible, which would not fit into RAM as a whole.
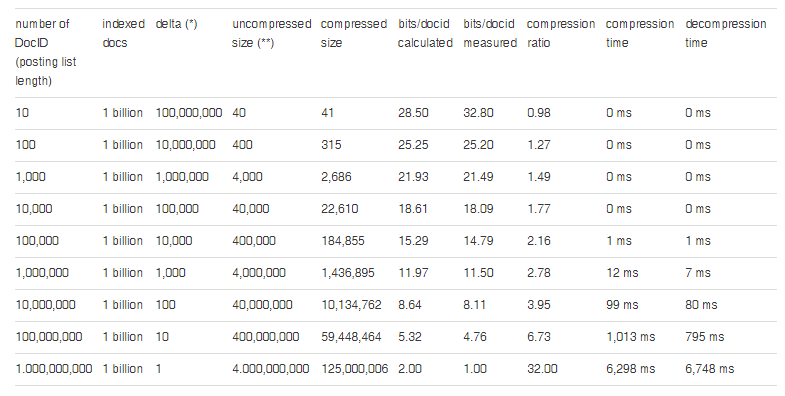
( * ) Delta d is the distance between two DocIDs in a sorted posting list of a certain term. Delta d depends on the length l of the posting list and the number of indexed pages (delta = gap = value range/number of values = number of indexed docs/posting list length). This also means that the term occurs every d pages, e.g. if delta d=10 then the term occurs on every 10th page. Delta is the only factor which determines the compression ratio (compressibility).
( ** ) 32 bit unsigned integer = 4 Byte/DocID.
Hardware: Intel Core i7–6700HQ (4 core, up to 3.50 GHz) 16 GB DDR4 RAM Software: Windows 10 64-Bit, .NET Framework 4.6.1
Tests were executed in a single thread, multiple threads would be used in a multi user/multi query scenario.
Index compression estimation
The compression ratio highly (and only) depends on the average delta between DocIDs/values (delta = gap = value range/number of values = number of indexed docs/posting list length). For frequent terms the average delta between DocIDs is smaller and the compression ratio higher (few bits/DocID), for rare terms the average delta between DocIDs is higher and the compression ratio lower (more bits/DocID). Therefore we need to know the term frequency (and thus the average delta between DocIDs of that term) for every term of the whole corpus to be indexed.
In order to calculate the compression ratio and the size of the whole compressed index (= the sum of all compressed posting lists, and not only the size of a single posting list) we have to take into account the distribution of the length of the posting lists respective the distribution of deltas between posting lists. The distribution of natural language follows the Zipf’s law.
Zipf’s Law, Heap’s Law and Long tail
Zipf’s Law states that the frequency of any word is inversely proportional to its rank in the frequency table. Thus the most frequent word will occur approximately twice as often as the second most frequent word, three times as often as the third most frequent word, etc. In an English corpus the word “the” is the most frequently occurring word, which accounts for 6% of all word occurrences. The second-place word “of” accounts for 3% of words (1/2 of “the”), followed by “and” with 2% (1/3 of “the”).
The probability Pr for a term of rank r can be calculated with the following formula: Pr= P1 * 1/r , where P1 is the probability of the most frequent term, which is between 0.06 and 0.1 in English depending on corpus. Phil Goetz states P1 as a function of the Vocabulary V (the number of distinct words) : P1=1/ln(1.78 * V)
In the Oxford English Corpus the following probabilities are observed (with P1≈0.09):

The vocabulary size v is the number of terms with rank r <= v. All probabilities derived from Zip’s law are approximations which differ between different corpora and languages.
Zipf’s Law is based on the Harmonic series ( 1 + 1/2 + 1/3 . . . + 1/n ). The divergence of the Harmonic series has been proved already 1360 by Nicole Oresme and later by Jakob Bernoulli. That means that the sum of the series H(n)=∞ for n=∞.
An approximation for the sum H(n) ≈ ln n + γ , where γ is the Euler-Mascheroni constant with an value of 0,5772156649…
Heaps’ law is an empirical law which describes the number of distinct words (Vocabulary V) in a text (document or set of documents) as a function of the text length: V = Kn^b where the vocabulary V is the number of distinct words in an instance text of size n. K and b are free parameters determined empirically. With English text corpora, typically K is between 10 and 100, and b is between 0.4 and 0.6.
Zipf’s law on word frequency and Heaps’ law on the growth of distinct words are observed in Indo-European language family, but it does not hold for languages like Chinese, Japanese and Korean.
The long tail is the name for a long-known feature of some statistical distributions (such as Zipf, power laws, Pareto distributions and general Lévy distributions). In “long-tailed” distributions a high-frequency or high-amplitude population is followed by a low-frequency or low-amplitude population which gradually “tails off” asymptotically. The events at the far end of the tail have a very low probability of occurrence.
As a rule of thumb, for such population distributions the majority of occurrences (more than half, and where the Pareto principle applies, 80%) are accounted for by the first 20% of items in the distribution. What is unusual about a long-tailed distribution is that the most frequently occurring 20% of items represent less than 50% of occurrences; or in other words, the least frequently occurring 80% of items are more important as a proportion of the total population.
Sources
- https://en.wikipedia.org/wiki/Long_tail
- https://en.wikipedia.org/wiki/Zipf%27s_law
- https://moz.com/blog/illustrating-the-long-tail
- https://blogemis.com/2015/09/26/zipfs-law-and-the-math-of-reason/
- http://mathworld.wolfram.com/ZipfsLaw.html
- http://www.cs.sfu.ca/CourseCentral/456/jpei/web%20slides/L06%20-%20Text%20statistics.pdf
Synthetic posting list creation
The distribution of the length of the posting lists follows Zipf’s law. But we have to distinguish positional posting list and non-positional posting list:
- Positional posting list can contain multiple postings per document. Frequent terms occur multiple multiple times per document, and each occurrence is stored together with its position within the document. This structure is helpful for supporting phrase and proximity queries.
- Non-positional posting list store only one posting per document. They record in which documents the term occurs at least once, the positions of the occurrences within the document are not stored.
For the creation of synthetic posting lists we need to calculate the length l of the posting list for every term. For positional posting lists we can use the following formula:
Posting list length (for term of rank r) : l = postings * MostFrequentTermProbability / r)
where
- postings = indexedDocs * uniqueTermsPerDoc
- indexedDocs is the number of all documents in the corpus to be indexed
- uniqueTermsPerDoc is about 300
- MostFrequentTermProbability is about 0.06 in an English corpus
- rank is the rank of the term in the frequency table. The term frequencies in the table are distributed by Zipf’s law.
- Postings is the number of all DocIDs in the index, which is the same as the sum of all postingListLength in the index.
For non-positional posting lists we can use the following formulas
Posting list length (for term with rank r) : l = Pterm_r_in_doc * indexedDocs
where
- probability of term with rank r (Zip’s law): Pterm_r = MostFrequentTermProbability / r
- probability of term with any rank other than r : Pterm_not_r = 1-Pterm_r
- probability of term with rank r occurs not in a doc (with t terms per doc): Pterm_r_not_in_doc = Pterm_not_r ^ t
- probability of term with rank r occurs at least once in a doc : Pterm_r_in_doc = 1 — Pterm_r_not_in_doc
The maximum posting list length l <= indexedDocs . This is because even if frequent terms occur multiple times within a document, in a non-positional index they are indexed only once per document. For each posting list we then create DocIDs up to the calculated Posting list length. The value of the DocIDs is randomly selected between 1 and indexedDocs. We have to prevent duplicate DocID within a posting list, e.g. by using a hash set to check whether a DocID already exists or not.
Real-world posting list data
While we are using synthetic data it is also possible to use real-world data for testing. There are several data sets available, although for some you have to pay:
Gov2: TREC 2004 Terabyte Track test collection, consisting of 25 million .gov web pages crawled in early 2004 (24,622,347 docs, 35,636,425 terms, 5,742,630,292 postings)
ClueWeb09: ClueWeb 2009 TREC Category B collection, consisting of 50 million English web pages crawled between January and February 2009 (50,131,015 docs, 92,094,694 terms, 15,857,983,641 postings)
The last two data sets are also available for free in a processed, anonymized form without term names. While in synthetic data the DocIDs are usually random, in Real-world data sets the cluster properties of docIDs (some terms are more dense in some parts of the collection than in others because the pages of a domain have been indexed consecutively) can be exploited. This may lead to additional compression.
Stop words and the resolving power of terms
H.P.Luhn wrote 1958 in the IBM Journal about the “resolving power of significant words”, featuring a word frequency diagram with the word frequencies distributed according to zipfs law. There he defined an lower and an upper cut-off limit for word frequencies, where only within that “sweet spot” the words where significant and had resolving or discriminatory power in queries. The terms outside the two limits would be excluded as non-significant, being too common or too rare. For the 20 most frequent terms this is very easy to comprehend: they are appearing in almost all documents of the collection and results would stay the same whether or not those terms are in the query.
For the most frequent words to be irrelevant and excluded, this resembles the concept of stop words. If we look at the 100 most common words in English we can immediately see the low resolving power. If we exclude the 100 most common words we lose almost nothing in result quality, but can significantly improve indexing performance and save space (50% for the Oxford English Corpus).
For 1 billion documents with 300 unique terms each we would spare 50 billion docIDs to be indexed. The Posting List for the most frequent term “the” alone would contain 1 million DocIDs, and the Posting List for the 100th popular term “us” would still contain 180 million DocIDs.
Of course we have to be careful when dealing with meaningful combinations of frequent words as “The Who” or “Take That”.
Index Compression Benchmark
The benchmark evaluates how well the Elias-Fano algorithm and our implementation perform for different numbers of indexed documents in respect to the key performance indicators (KPI) compression ratio, compression time and decompression time. This time we are benchmarking the whole index (all documents from a corpus are indexed) instead of single posting lists.
Again we are using synthetic data for the reasons stated above.
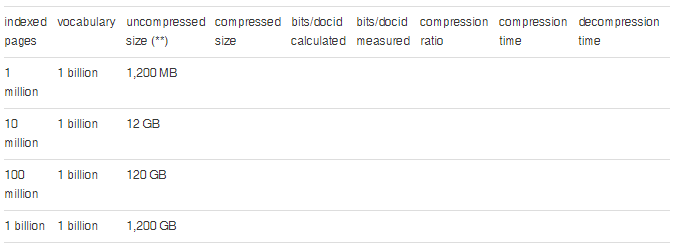
( * ) average word length, vocabulary, including/excluding 100 most frequent words (stop words). Do not contribute to meaningful results (paper)
( ** ) Uncompressed index size = 300 unique words/page * number of indexed pages * byte/DocID (32 bit unsigned integer = 4 Byte/DocID)
Hardware: Intel Core i7–6700HQ (6MB Cache, up to 3.50 GHz) 16 GB DDR4 RAM
Software: Windows 10 64-Bit, .NET Framework 4.6.1
Compressed intersection
Over 70% of the web queries contain multiple query terms. For those Boolean queries intersecting the posting lists of all query terms is required. When posting lists are compressed, they need to be uncompressed before or during the intersection.
Naive approach: decompress the whole posting lists for each query term and keep them during the intersection in RAM. This leads to high decompression time and memory consumption.
Improved approach: decompress only the currently compared items of the posting lists on the fly and discard them immediately after comparison. Terminate the decompression and intersection as soon as top-k ranked results are retrieved.
Github
The C# implementation of the Elias-Fano compression is released on GitHub as Open Source under the GNU Lesser General Public License (LGPL):
https://github.com/wolfgarbe/EliasFanoCompression
- EliasFanoInitTable
- EliasFanoCompress
- EliasFanoDecompress
- SortedRandomIntegerListGenerator: generates a sorted list of random integers from 2 parameters: number of items (length of posting list), range of items (number of indexed pages)
- ZipDistributedPostingListGenerator: generates complete set posting lists with zipfian distributed length (word frequency)