
SeekStorm sharded index architecture - using a multi-core processor like a miniature data center

Photo by Jim Witkowski
TLDR : 4..6x faster indexing & 3x faster search
Never settle! SeekStorm already excels at query latency and throughput. But there is always room for improvement.
Time to tackle indexing speed and quadruple down on query latency.
Sharding
A shard is a horizontal partition of data in a database or search engine.
Usually, each shard is held on a separate database server instance, to both spread indexing and query load and split a large index across multiple servers.
Distributing an index over multiple shards and servers allows scaling index size, indexing speed, query load, and query latency beyond the capacity of a single server.
Benefits
- faster indexing
- faster searching
- higher throughput
- larger index size
This principle has been used e.g. by Google* “WEBSEARCH FOR A PLANET: THE GOOGLE CLUSTER ARCHITECTURE” and Elastic* search.
SeekStorm moves this very same principle from a macro level to a micro level.
Instead of multiple servers, with a shard (index partition) per server, we use multiple processor cores, with a shard (index partition) per processor core.
In both cases, indices are document partitioned across shards during indexing, and partial results from each shard are aggregated during the search into the final results.
This allows the full utilization of all processor cores, without synchronization and locking losses.
It increases the indexing speed and reduces the query latency by enabling intra-query parallelism.
Indexing time and query latency always scale with the number of shards, whether multiple processor cores, multiple servers, or both.
A query always touches all shards and processor cores, but the sub-index size and work per shard and processor core are only a fraction compared to an index without shards.
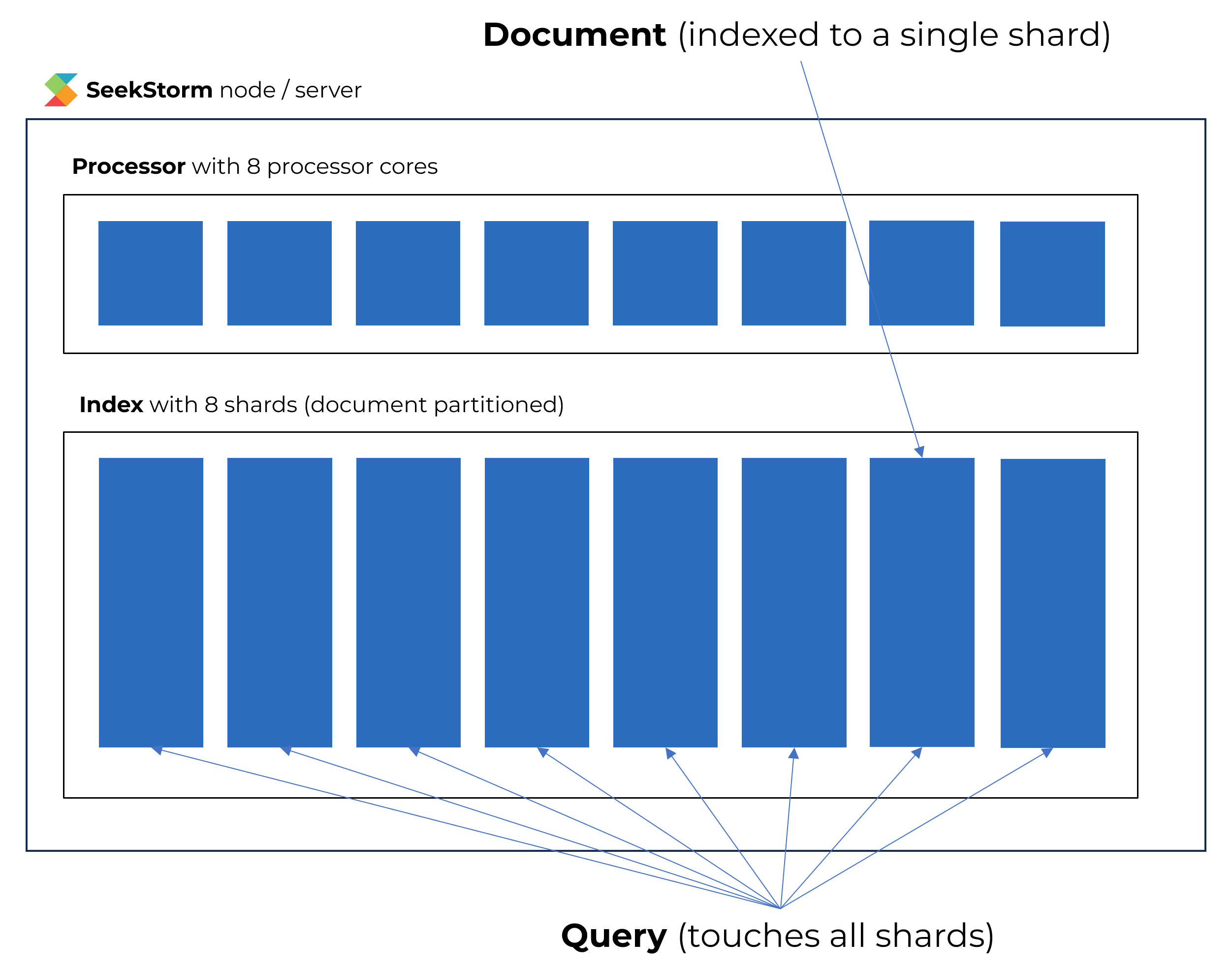
The beauty of this architectural principle/pattern is that it universally applies for scaling to both multi-server and multi-processor designs.
Seekstorm essentially treats a processor with many processor cores as a miniature data center with many servers.
That approach becomes more attractive as the number of cores in modern processors increases: e.g. AMD* Ryzen 9 9950X has 16 cores (32 threads) or Intel* Core i9 14900 has 24 cores (32 threads).
While in the past search engines were designed with multithreading as an afterthought at best, to fully utilize the power of modern processor architectures require to design search engine architecture with multithreading-first in mind.
A server almost never runs at full utilization, allowing for headroom to handle traffic spikes and growth. This unused idle computing capacity can be utilized by the sharded index architecture to reduce query (tail) latency.
Challenges of BM25 ranking in a sharded index
Partitioning a search index in multiple shards can significantly improve both indexing speed and query latency.
Having independent sub-indices enables intra-query parallelism and allows the utilization of all processor cores without synchronization and locking issues.
But new challenges arise:
BM25 scores are only fully comparable within a single shard, but not across multiple shards. And they are also not comparable between a sharded index and a non-sharded index, even if the same set of documents is indexed. The reason for this becomes obvious if we look at the BM25 formulae shown below. The BM25 score not only depends on the properties of a given document (like term frequency or document length), but also on values averaged and summarized across all documents in the index or shard. Aggregated BM25 components like the number of documents, posting list length (term frequency), and average document length differ between shards and also between a normal index and a sharded index. When we later aggregate the top-k results of each shard into the final top-k results the sorting of results by scores from different shards is flawed. The more the number and the content of documents indexed differs between the shards, the less comparable are the BM25 scores from different shards.
The distribution of documents across the shards is not deterministic but relies on load-balancing that depends on the current utilization of shards/processor cores. That means aggregated BM25 components, the resulting BM25 scores within shards, and the final top-k results and their scores are non-deterministic and may change after reindexing the same documents.
All those challenges can be overcome, but they add extra complexity on top of a seemingly simple idea.
For SeekStorm’s sharded index, where documents are evenly distributed across shards, the BM25 scores can be compared between shards. There might be slight differences in the order of results compared to a scoring in a non-sharded index, but those are mainly negliable.
But when different content distribution strategies are employed, e.g., when a new shard is added on a new node, because the capacity limit of the other shards was reached, then we need to do re-scoring of the top-10 results aggregated from the different shards .
The typical BM25 formula
K = 1.2;
B = 0.75;
SIGMA = 0.0;
DF = document frequency = posting_count = posting list length = number of documents containing the term
TF = term frequency in document = positions_count = positions of term in document = how often occurs term in doc
IDF = (((indexed_doc_count- DF + 0.5) / (DF + 0.5)) + 1.0).ln(); //log_e
document_length_quotient= doc_len / avg_doc_len
BM25 = IDF * ((TF * (K + 1.0) / (TF + (K * (1.0 - B + (B * document_length_quotient))))) + SIGMA);
The formulae gets slightly more complex if multiple indexed fields are involved and we need to aggregate the BM25 scores per field (BM25f).
In order to re-score the results from different nodes, we need those components of the BM25 formulae that differ between the shards:
New fields per top-k result set
- document_frequencies:Vec<(term_hash,DF)>
- indexed_doc_count
- doc_len_sum
New fields per top-k result
- term_frequencies:Vec<(term_hash,TF)>
- doc_len
Re-scoring
- We need to calculate the global document_frequencies (DF) per query term by summing the DF from all shards per query term.
- We need to calculate the global avg_doc_len by dividing the sum of all doc_len_sum from all shards by the sum of all indexed_doc_count from all shards.
- Then we can use those individual and global values in the BM25 formulae above to re-score the documents coming from different shards on a common base.
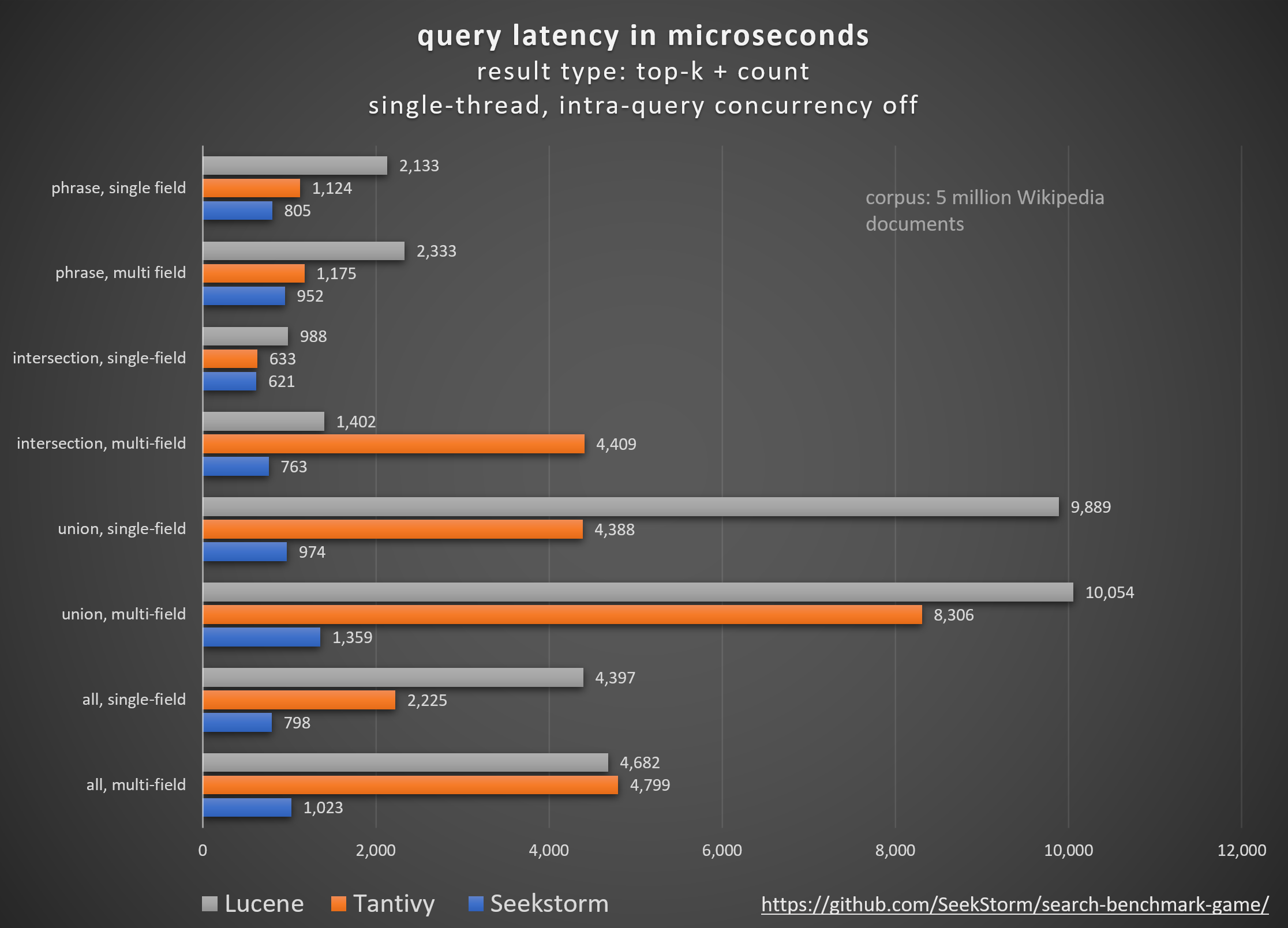
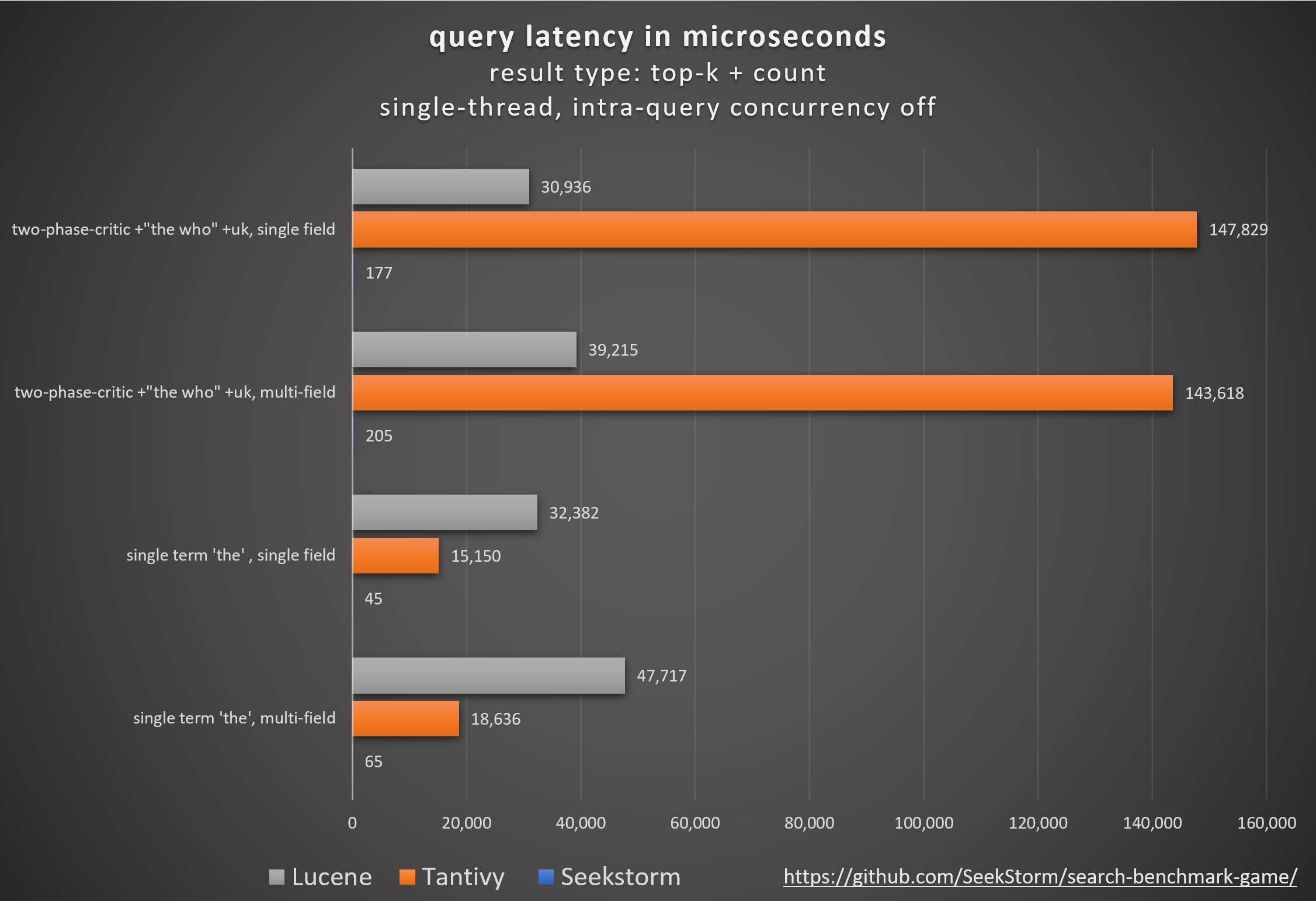
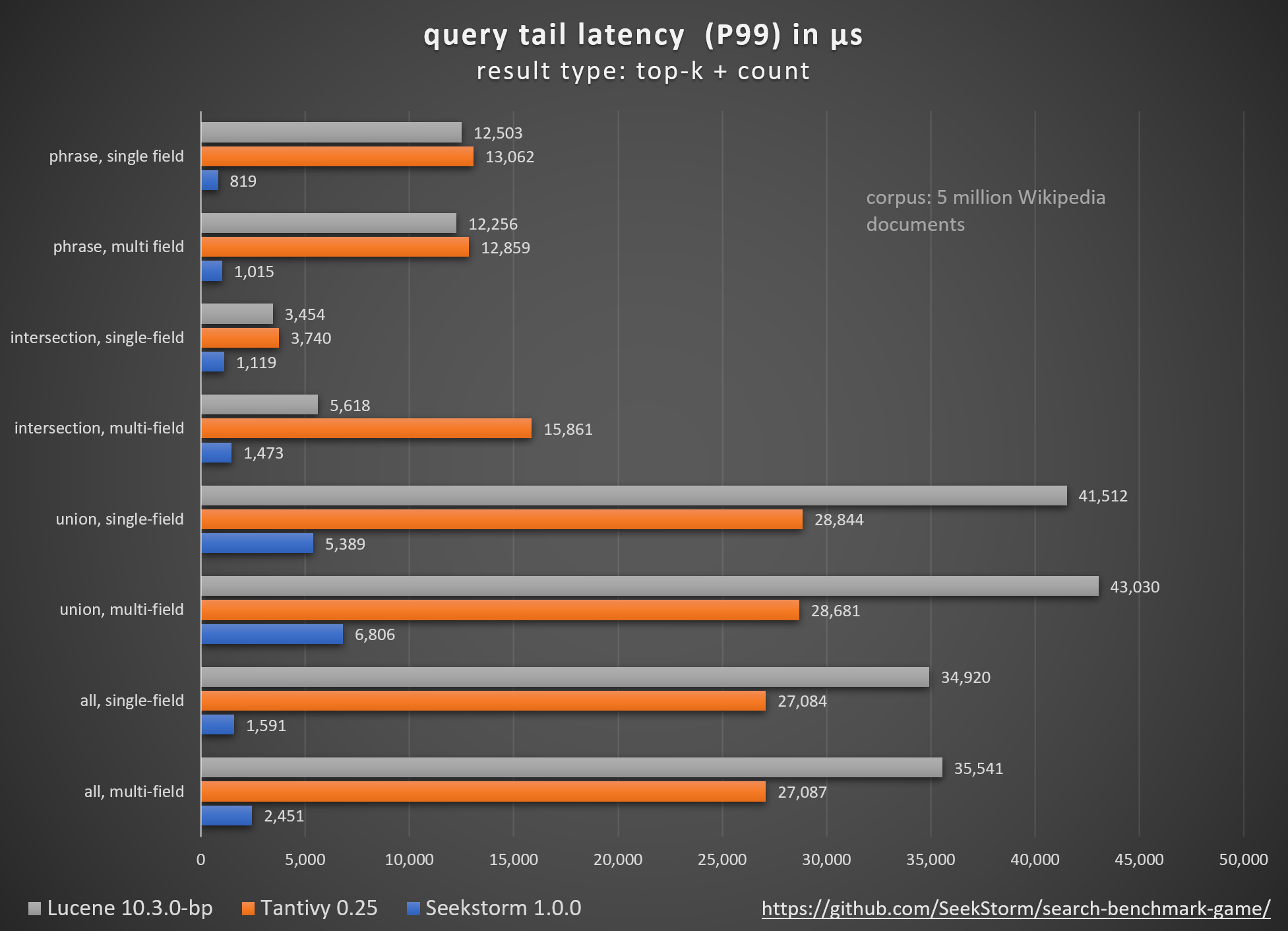
4..6x faster indexing & 3x faster search
SeekStorm’s key advantage is a faster search at lower infrastructure cost. Fast search performance is crucial, especially for large indices, which also demand rapid data ingestion.
Our new sharded index architecture features an index with document-partitioned shards, allowing for lock-free, multi-threaded indexing. This fully utilizes all processor cores and increases ingestion speed by a factor of five. The sharded index also enables intra-query concurrency, decreasing average query latency by four times for non-concurrent loads.
A sharded index enables not only a higher indexing speed but also improves query latency by utilizing all processor cores. But the latter doesn’t yet utilize its full potential. Each shard sees only its own result, and can’t access the results retrieved in parallel from other shards for optimum early termination. The benefit through sharding and parallelization outweighs by far the tunnel vision per shard and the resulting non-optimal early termination. However, the full potential is only unleashed by allowing information to be exchanged between shards during the search.
Beginning with release v1.0.0, the SeekStorm lexical search library implements a sharded index, enabling 4..6x faster indexing and 3x shorter query latency with intra-query parallelism, when comparing SeekStorm v1.0.0 to v0.14.1. 5 million Wikipedia documents are indexed at 40,000 docs/sec (3.5 billion docs/day), and searched with 0.25 ms average query latency, reaching 10,000 queries/sec throughput.
All of the above has been measured using search_benchmark_game queries and English Wikipedia corpus, on a Intel Core i7 13700h laptop. Of course, benchmark results highly depend on used queries, corpus and hardware, but the results give a clear indication of the improvements achieved since the previous SeekStorm version.
Benchmark
Download
SeekStorm v1.0.0 excels in both indexing and search performance and is available as open source on GitHub.
Roadmap
Currently we support a single node (server) with multiple local index shards. In the next step we will support a cluster, where each shard can be either a local shard or a remote node (dedicated server or cloud) with multiple shards.
This will allow to dynamically increase index capacity by adding more servers.
(*) All mentioned trademarks and proper names belong to their respective owners and do not imply any affiliation or any other kind of alliance with their respective owners.