
🔥SeekStorm 3.0 adds vector search & hybrid search

SeekStorm uses two separate, first-class, native index architectures, under one roof.
- Lexical search (sparse retrieval): sharded and leveled inverted index.
- Vector search (dense retrieval): sharded and leveled IVF index for ANN or exhaustive search.
- Shared document store, shared document ID space.
- Both first-class engines are integrated at the query planner level.
- Query planner with QueryModes (Lexical, Vector, Hybrid…) and FusionTypes (RRF, …).
Why hybrid search?
Because lexical search and vector search complement each other. We can significantly improve result quality with hybrid search by combining their strengths, while compensating their shortcomings.
- Lexical search is fast, precise, exact, and language independent - but unable to deal with meaning and semantic similarity.
- Vector search understands similarities - but is language dependent, can’t deal with new or rare terms it wasn’t trained for, it is slower and more expensive.
Keyword search (lexical search)
If you search for exact results like proper names, numbers, license plates, domain names, and phrases (e.g. plagiarism detection) then keyword search is your friend. Vector search, on the other hand, will bury the exact result that you are looking for among a myriad of results that are only somehow semantically related. At the same time, if you don’t know the exact terms, or you are interested in a broader topic, meaning or synonym, no matter what exact terms are used, then keyword search will fail you.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
- works with text data only
- unable to capture context, meaning and semantic similarity
- low recall for semantic meaning
+ perfect recall for exact keyword match
+ perfect precision (for exact keyword match)
+ high query speed and throughput (for large document numbers)
+ high indexing speed (for large document numbers)
+ incremental indexing fully supported
+ smaller index size
+ lower infrastructure cost per document and per query, lower energy consumption
+ good scalability (for large document numbers)
+ perfect for exact keyword and phrase search, no false positives
+ perfect explainability
+ efficient and lossless for exact keyword and phrase search
+ works with new vocabulary out of the box
+ works with any language out of the box
+ works perfect with long-tail vocabulary out of the box
+ works perfect with any rare language or domain-specific vocabulary out of the box
+ RAG (Retrieval-augmented generation) based on keyword search offers unrestricted real-time capabilities.
Vector search
Vector search is perfect if you don’t know the exact query terms, or you are interested in a broader topic, meaning or synonym, no matter what exact query terms are used. But if you are looking for exact terms, e.g. proper names, numbers, license plates, domain names, and phrases (e.g. plagiarism detection) then you should always use keyword search. Vector search will instead bury the exact result that you are looking for among a myriad of results that are only somehow related. It has a good recall, but low precision, and higher latency. It is prone to false positives, e.g., in plagiarism detection as exact words and word order get lost.
Vector search enables you to search not only for similar text, but for everything that can be transformed into a vector: text, images (face recognition, fingerprints), audio, enabling you to do magic things like “queen - woman + man = king.”
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
+ works with any data that can be transformed to a vector: text, image, audio ...
+ able to capture context, meaning, and semantic similarity
+ high recall for semantic meaning
- lower recall for exact keyword match (for Approximate Similarity Search)
- lower precision (for exact keyword match)
- lower query speed and throughput (for large document numbers)
- lower indexing speed (for large document numbers)
- incremental indexing is expensive and requires rebuilding the entire index periodically, which is extremely time-consuming and resource intensive.
- larger index size
- higher infrastructure cost per document and per query, higher energy consumption
- limited scalability (for large document numbers)
- unsuitable for exact keyword and phrase search, many false positives
- low explainability makes it difficult to spot manipulations, bias and root cause of retrieval/ranking problems
- inefficient and lossy for exact keyword and phrase search
- Additional effort and cost to create embeddings and keep them updated for every language and domain. Even if the number of indexed documents is small, the embeddings have to created from a large corpus before nevertheless.
- Limited real-time capability due to limited recency of embeddings
- works only with vocabulary known at the time of embedding creation
- works only with the languages of the corpus from which the embeddings have been derived
- works only with long-tail vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- works only with rare language or domain-specific vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- RAG (Retrieval-augmented generation) based on vector search offers only limited real-time capabilities, as it can't process new vocabulary that arrived after the embedding generation
Vector Features
- Multi-Vector indexing: both from multiple fields and from multiple chunks per field.
- Integrated inference from any text document field or Import external embeddings.
- Variable dimensions and precisions: f32, i8.
- Scalar Quantization (SQ).
- Multiple similarity measures: Cosine similarity, Dot product, Euclidean distance.
- Chunking that respects sentence boundaries and Unicode segmentation for multilingual text.
- K-medoid clustering with actual data points as centers.
- Field filters are active during vector search, not just as post-search filtering step.
- True real-time search
- disk-based billion-scale vector search
- Sub-millisecond search for 1 million vectors on a laptop, CPU only:
Sift1M recall@10=95%, 0.2 ms recall@10=99%, 0.3 ms
See CHANGELOG.md for details.
Dual Engine Architecture for Hybrid Search
- Internally, SeekStorm uses two separate, first-class, native index architectures for vector search and keyword search. Two native cores, not just a retrofit, add-on layer.
- SeekStorm doesn’t try to make one index do everything. It runs two native search engines and lets the query planner decide how to combine them.
- Two native index architectures under one roof:
- Lexical search (sparse retrieval): an inverted index optimized for lexical relevance,
- Vector search (dense retrieval): an ANN index optimized for vector similarity.
- Both are first-class engines, integrated at the query planner level.
- Query planner with dedicated QueryModes and FusionTypes
- Query planner mode can be automatically or manually selected.
- Active QueryModes mode is returned for explainability, relatability and credibility.
- Separate internal index, storage layouts, indexing, search, scoring, top-k candidates - unified query planner and result fusion (Reciprocal Rank Fusion - RRF).
- But the user is fully shielded from the complexity, as if it was only a single index.
- Enables pure lexical, pure vector or hybrid search (exhaustive, not only re-ranking of preliminary candidates).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
┌────────────────────┐
│ User / API │
│ (hybrid query) │
└─────────┬──────────┘
│
▼
┌────────────────────┐
│ Query Planner │
│ (intent + strategy)│
└───────┬───────┬────┘
│ │
┌──────────────┘ └──────────────┐
▼ ▼
┌────────────────────┐ ┌────────────────────┐
│ Lexical Engine │ │ Vector Engine │
│ Inverted Index │ │ Native ANN Index │
│ (BM25 / Boolean) │ │ (Leveled‑IVF) │
└─────────┬──────────┘ └─────────┬──────────┘
│ │
▼ ▼
Ranked Results L Ranked Results V
│ │
└───────┬───────────────┬─────────┘
▼ ▼
┌────────────────────────────┐
│ Result Fusion │
│ (RRF / rerank strategies) │
│ │
└────────────┬───────────────┘
▼
Final Ranked Results
Leveled IVF index (vector)
- Disk-based, Leveled IVF index for unlimited index size.
- Sharded index for lock-free utilization of all processor cores.
- true real-time indexing and search capable.
- Approximate Nearest Neighbor Search (ANNS) and exhaustive k-nearest neighbor search (kNN)
- K-Medoid clustering: PAM (Partition Around Medoids) with actual data points as centers.
Benchmark vector search (SIFT1M, GIST1M)
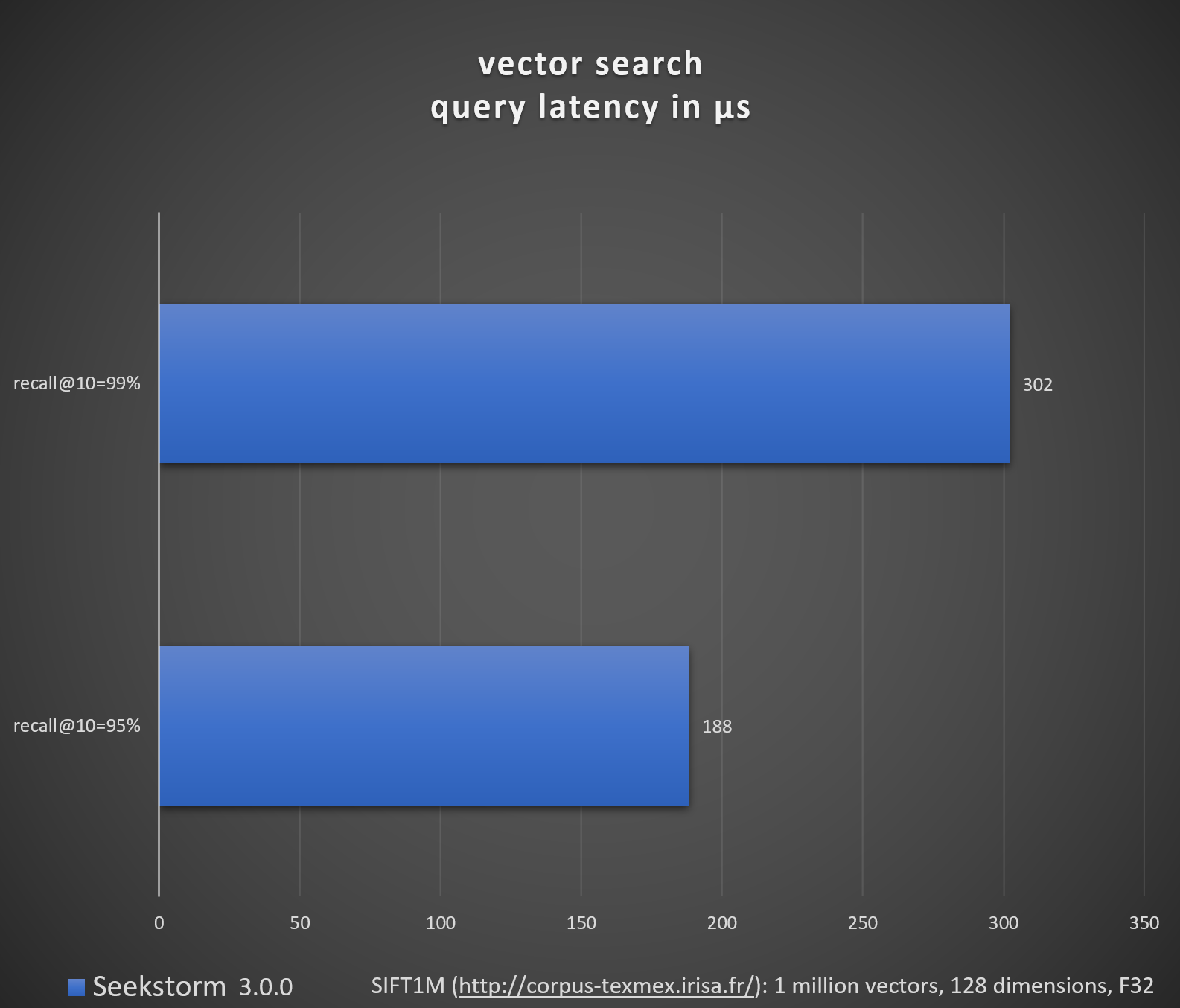
SIFT1M dataset 1 million vectors, 128 dimensions, f32 precision, Euclidean
- 8-bit Scalar Quantization, nprobe=16 -> recall@10=95%, average latency=188 microseconds
- 8-bit Scalar Quantization, nprobe=33 -> recall@10=99%, average latency=302 microseconds
GIST1M dataset 1 million vectors, 960 dimensions, f32 precision, Euclidean
- 8-bit Scalar Quantization, nprobe=38 -> recall@10=95%, average latency=3,198 microseconds
- 8-bit Scalar Quantization, nprobe=80 -> recall@10=98%, average latency=5,737 microseconds
Benchmark vector search vs. lexical search (Wikipedia)
There are benchmarks of vector search engines, and benchmarks of lexical search engines.
But seeing the latency of lexical search and vector search stacked up against each other might offer some unique insight.
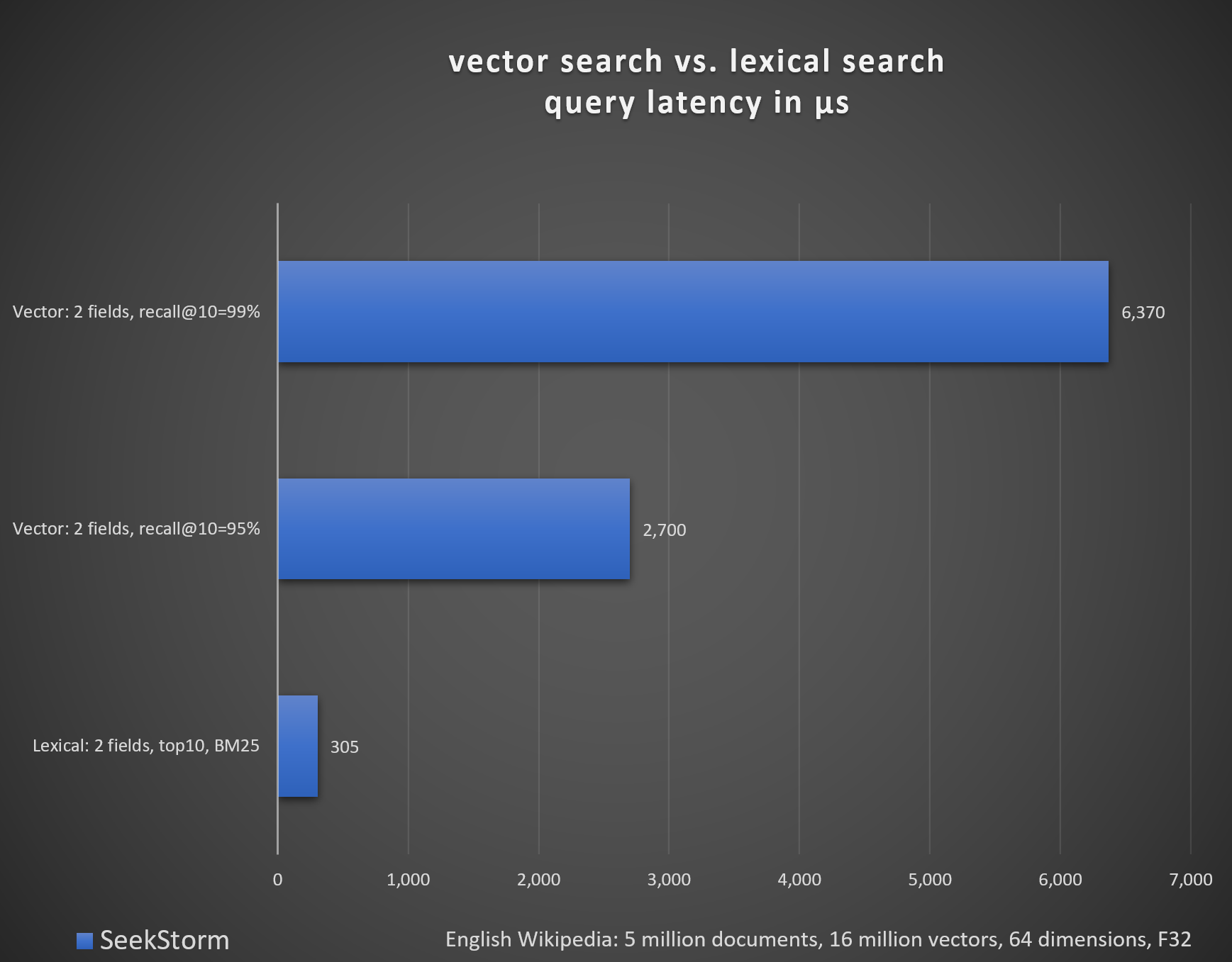
English Wikipedia: 5 million documents, 16 million vectors
Lexical: 2 fields, top10, BM25, average latency 305 microseconds
Vector: 2 fields, nprobe=68 -> recall@10=95%, average latency 2,700 microseconds
Vector: 2 fields, nprobe=200 -> recall@10=99%, average latency 6,370 microseconds
Using Model2Vec from MinishLab: PotionBase2M, chunks: 1000 byte
We are using the English Wikipedia data (5 million entries) and queries (300 intersection queries) derived from the AOL query dataset, both from Tantivy’s search-benchmark-game.
Repository
SeekStorm: vector & lexical search - in-process library & multi-tenancy server, in Rust.
SeekStorm is open-source, under the Apache-2.0 license, available at our GitHub repository.