
Typo-tolerant Query auto-completion (QAC) - derived from indexed documents
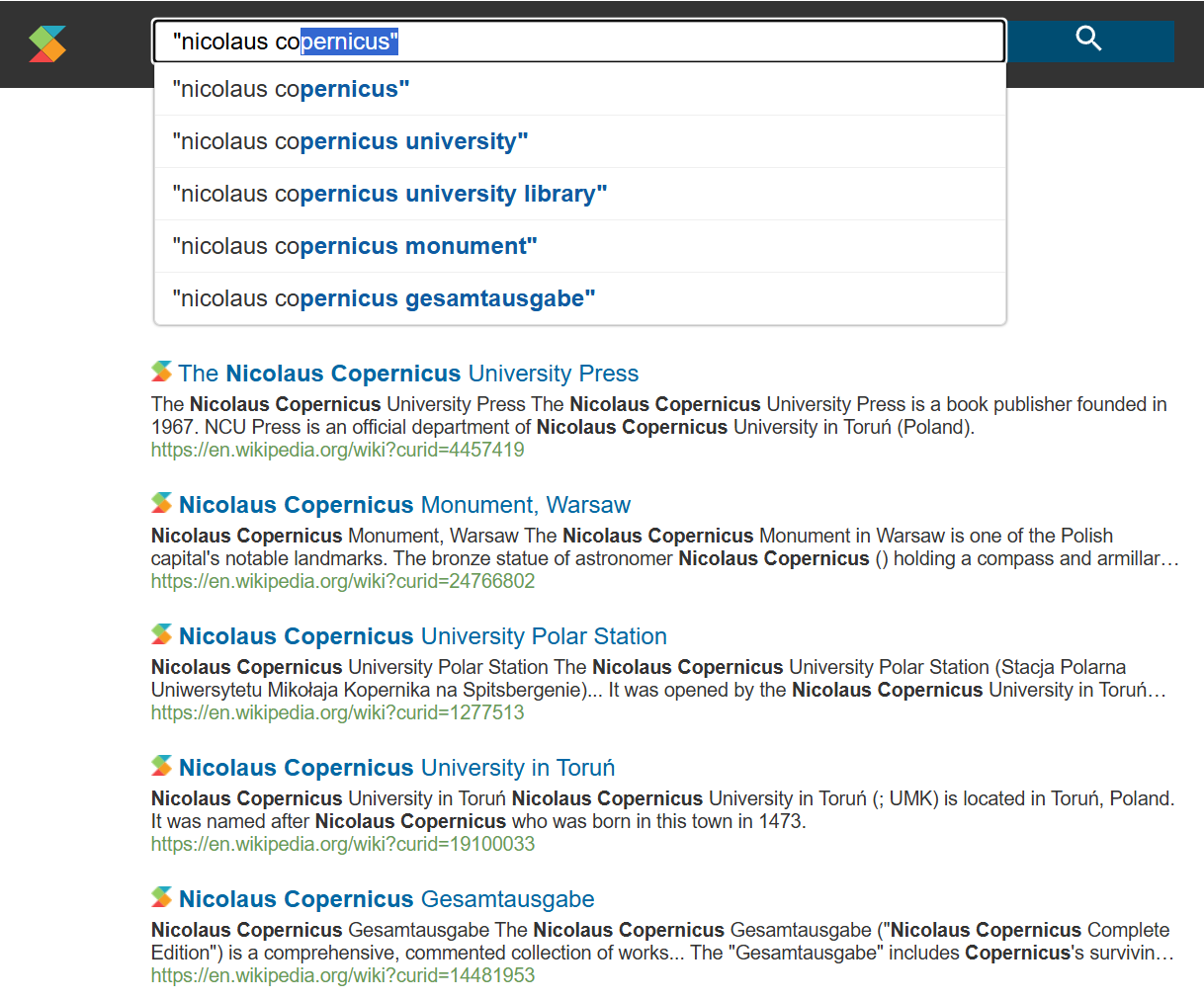
— work in progress, live reporting from the lab 😀 —
TLDR : Typo- and word-order tolerant Query auto-completion (QAC) - derived from indexed documents instead of from query logs
Providing the user with query completions while typing has many benefits: it saves time, prevents and corrects spelling mistakes, makes sure queries are aligned with index content, helps the user to formulate queries if he is unsure about the terms, their spelling or the content of the index.
But implementing QAC at scale also comes with many challenges: how to collect, count and select the completions, with low memory requirement, low performance impact, and high relevance. And how to rank and serve them to the user with low latency, even for large indices and many concurrent users.
In the blog post we analyze those challenges, explore the solution space and present our open source implementation - both our standalone library SymSpellComplete as well as its integration into our SeekStorm search library and server.
This blog post describes two components of our recent work to build a typo-tolerant Query auto-completion (QAC) system, where the completions are derived from indexed documents as opposed from query-logs. We discuss our research into prior art and related work, algorithms, data structure, challenges in scaling and resource consumption, experiments and our final solution.
SymSpellComplete, a typo- and word-order tolerant autocomplete library in Rust.
Like a combination of SymSpell (repo) and PruningRadixTrie (repo), but better:
- Typo-tolerant & word-order tolerant.
- Query terms might contain spelling errors, even in the first letter of an incomplete term:
blu kura->blue curacao - Handles missing and mistakenly inserted spaces:
modernart->modern art - Supports differing order between query and completion terms:
university dre->dresden university of technology - Allows out-of-vocabulary terms (not all query terms are present in completions):
teal merino cardi->merino cardigan - Multi-term completions using term co-occurrence probabilities for ranking.
- The SymSpellComplete library is implemented in Rust, and available as open-source under the MIT license.
Typo- and word-order tolerant Query Auto-Completion (QAC) in the SeekStorm full-text search library & multi-tenancy server, using SymSpellComplete.
- The completions are automatically derived in real-time from indexed documents, not from a query log.
- works, even if no query log is available, especially for domain-specific, newly created indices or few users.
- works for new or domain-specific terms.
- allows out-of-the-box domain specific suggestions
- prevents inconsistencies between completions and index content.
- Query logs contains invalid queries: because its sourced from a different index or because users don’t know the content of your index..
- Works for the long tail of queries, that never made it to a log.
- suggestions tailored per index.
- completion prevents spelling errors and saves time
- language-, content- and domain-independent
- additionally allows to use hand crafted completion files
- Ghosting: highlighting the suggested text within the search box in the UI
- The SeekStorm lexical search library and server are implemented in Rust, and available as open-source under the MIT license.
Table of contents
- Problem statement and desired functionality
- Integral functionality vs. external component
- Query and completion lengths
- Completion data sources
- Completion lookup methods
- Query spelling correction
- Combining spelling correction and completion
- UI integration of completions
- Completions and search operators
- Completions, tokenizers and stemming
- Serialization and compression of completion lists
- Removing outdated completions
- Scaling challenges
- Tests: What to measure?
- Benchmarks
- Usage
- Availability
Problem statement and requirements
Why query completion?
Providing the user with query completions while typing has many benefits:
- it saves time, prevents and corrects spelling mistakes,
- makes sure queries are aligned with index content,
- helps the user to formulate queries if he is unsure about the terms, their spelling or the content of the index.
- query completions help to prevent queries that lead to zero results.
Feuer et al. analyzed more than 1.5 million queries from search logs of a commercial search engine and found that query suggestions accounted for roughly 30% of all the queries indicating the important role played by query suggestions in modern information retrieval systems. Furthermore, Kelly et al. observed that the use of offered query suggestions is more for difficult topics, i.e., topics about which users have little knowledge to formulate good queries.
Those numbers may vary, depending on the coverage of completions, their quality, the domain and changing user behavior. You should ultimately always do your own experiments and measurements with your own data and users.
But implementing QAC at scale also comes with many challenges: how to collect, count and select the completions, with low memory requirement, low performance impact, and high relevance. And how to rank and serve them to the user with low latency, even for large indices and many concurrent users.
Could we get away with simply adding a library like PruningRadixTrie and feeding it with a word frequency list like those from SymSpell? Sure, we can - but we would sacrifice a lot of functionality we could achieve otherwise:
Desired functionality
- multi-term completions
- no discrepancy between completions and indexed document content
- support for new and domain-specific terms
- support for index specific completions and their rankings
- language independence
- prefix or substring lookup
- typo-tolerant completion
- deal with spelling errors in both complete and incomplete terms, including the first letter
- word-order tolerant completion
- identify completions where all the query terms appear as prefixes of some of the terms of the completions, regardless their order.
- score completions by word and n-gram frequency, derived from the corpus, for high relevancy.
- low resource impact of completion generation, storage, and lookup: RAM, disc, processor, IO
- fast lookup time
- dynamic, self-learning from a stream of documents as opposed to immutable one-time batch generation
- scaling: preventing unlimited growth of completions lists and resource consumption as the index grows
- Integration of completions into the UI
On of the biggest challenges in search is the gap between query-term space and document-term space. Users will always blame our search or our content, and not their deficiencies to search. We should give the use all assistance possible to close that gap, in order not not lose our users and/or revenue.
Integral functionality vs. external component
More functionality usually comes with more complexity (and bulk if it is not needed). Having a bare-bone search library, which is both performant and easy to understand, while you can add any functionality you want to your pipeline with external components of your choice, has a beauty of its own.
In search, high-performance core technology is paramount, as is keeping things simple, and preventing complexity - but integrating more building blocks makes it more accessible, appealing to a wider audience, reduces the time to market, and keeps the overall system even less complex despite added functionality, given the following preconditions
- functionality that the user almost always anyway needs, otherwise requiring additional pre- or post-processing components.
- that the functionality is non-trivial to add and integrate.
- that the functionality benefits from a deeper integration with the core indexing and search technology (e.g. using the tokenizer, plugging into commit, multi-tenancy and per index customization …).
- there are no external components available, that check all the boxes of the desired functionality listed above.
Challenges
- Using the same corpus for query spelling correction (dictionary generation) and query completion (completion list generation) as for indexing and search, to prevent suggesting queries that lead to zero results.
- Using the same tokenizer for query spelling correction (dictionary generation, lookup) and query completion (completion list generation, lookup) like for indexing and search.
- Take into account CJK word segmentation for query spelling correction and query completion.
- Allow and preserve query operator chars like + - “” during query spelling correction and completion.
- Do not use NOT (-) terms for query completion, neither for input prefix, nor for output suggestions.
Phrase completions - Allow, preserve and complete phrase chars “” during query spelling correction & completion.
Currently, query correction/completion supports phrases “”, but is disabled if +- operators are used, or if a opening quote is used after the first term, or if a closing quote is used before the last term.
Reporting from my experience, having word frequency lists (uni-gram and bi-gram), spelling correction and auto completion libraries readily available, and as author, deep knowledge of those libraries as well as of the search engine library, it took several weeks of research, experimenting, implementing, integrating until the results met my expectations and the desired functionality. It is always more complex than you think in the beginning, and we wanted to remove the need to reinvent the wheel for a functionality that almost everyone using a search engine benefits from.
Just by reading the table of contents of this blog post you probably already know, that implementing query auto-completion yourself, even by using available libraries, would be a substantial endeavor.
Sure, the last percents of perfection in your domain you get only with a fully customized pipeline, including deep integration into the search engine codebase, specifically designed for your users, for your data, for your use case, but that requires a significant amount time, budget, and expertise.
For many users, a turn-key solution that just works, at no extra cost, is preferable, at least for the start.
Query and completion lengths
Query lengths hugely depends on the type of search e.g. (e-commerce vs. web), the domain (sport, entertainment, legal, scientific research), and the experience of the searcher. Currently, most of the queries consist of 4 or less terms, but with the advent of LLM that is changing.
While we would like to provide query completions for any number of query terms the user enters, the resource consumption required to extract completions grows exponentially with the number of query terms.
A limit of n=3 for the number of consecutive terms (unigrams, bigrams, trigrams) to extract as completion candidates is the maximum we can afford in terms of resource consumption.
But we can mitigate this limitation with a Sliding window completion.
Completion data sources
There are three approaches to obtain and distill query completion data:
From query logs
Deriving completions from a query log is the most popular approach, with both pros and cons:
Benefits
- user curated: real users with quantifiable interest in those queries
- usage-driven vs. content-driven suggestion ranking.
Drawbacks
- logs with invalid queries lead to invalid completions: misspelled terms, query doesn’t return results because there are no matching documents indexed.
- outdated query logs, missing completions: query popularity, missing new or domain specific terms and queries. Often suggestions are created once, and not updated or only with delay, when new documents with new terms are indexed.
- difficult to obtain: representative and statistically sufficient query logs, especially for new and domain specific indices with limited prior usage.
- privacy concerns: see https://en.wikipedia.org/wiki/AOL_search_log_release
- divergence between completion and indexed content: completions might be suggested for which no matching documents can be found in the index.
- due to the long-tail nature of queries, most of the queries have never been seen before. This also means for most queries completion solely based of query logs won’t work.
See AmazonQAC: A Large-Scale, Naturalistic Query Autocomplete Dataset
From document corpus
Deriving completions from indexed documents is an alternate approach, also with both pros and cons.
There is an interesting paper Query Suggestions in the Absence of Query Logs by Sumit Bhatia, Debapriyo Majumdar, Prasenjit Mitra that introduces the general idea of deriving query completions by extracting n-grams (uni-grams, bi-grams and tri-grams) from the document corpus instead from the usual query log. Using the extracted set of completion n-grams, the paper also investigates the ranking and precision of query completions generated by different query suggestion methods.
Unfortunately, both the principal drawbacks of the approach and the challenges when scaling it to production are not discussed.
Benefits
- The completions are automatically derived in real-time from indexed documents, not from a query log:
- works, even if no query log is available, especially for domain-specific, newly created indices or few users.
- works for new or domain-specific terms.
- allows out-of-the-box domain specific suggestions
- prevents inconsistencies between completions and index content. Query logs contains invalid queries: because its sourced from a different index or because users don’t know the content of your index..
- Works for the long tail of queries, that never made it to a log.
- content-driven vs. usage-driven suggestion ranking.
Challenges
- there are no consideration about scaling the approach for large indices, and the challenges that come with it,
- RAM, disk and processor consumption and limits,
- n-gram extraction performance,
- lookup performance,
- completeness of suggestions,
- effective storage and compression of completions,
- measures to reduce resource consumption (term frequency thresholds, capping the number of stored completions), while achieving a good cost (processor, disk space, RAM consumptions) vs. precision and recall ratio,
- realtime updates and availability of suggestions from a document stream as opposed to a one-time batch processing leading to static immutable completions,
- how to deal with non-uniformly distributed terms and n-grams, e.g. new products occurring late, or only within a specific range of documents
- typo-tolerance, especially when typos at the beginning of the word prevent the use of tries.
Drawbacks
- There are many term combinations created that will be never searched, making it inefficient both for creation time, resource consumption and storage requirements, and difficult to scale for large indices. Brute force is expensive. The challenge is similar to writing an abstract from a large document or deciding which words and passages to highlight in bold.
- Only completions are created and counted, that appear as consecutive terms within a maximum distance of 3 (trigrams) within the indexed documents. Most users are trained to enter only those terms that make the essence of the question. Those terms can be non-consecutive, because natural language is verbose, filled with many words caused by grammar rules. But sometimes queries refer to terms that are accepted to appear in different places in the document, like the query
louvre ticket price- while in the document the terms appear asLouvre ... Location ... Ticket ... Where to buy ... Price .... Sometimes, but not always, those completions will be anyway created, because they appear together in close proximity in other documents. And deriving completions from all term combinations that appear anywhere within a documents (beyond those that are consecutive) is just not feasible because of the amount of combinations that would be created and the difficulty to automatically distinguish between combinations that are useful and those that are just a waste of time and space. - Significant time and space complexity: A quick baseline experiment shows, that deriving and counting all unique unigram, bigram and trigram completions from a 5,032,105 document Wikipedia corpus with a naive hashmap approach in the tokenizer lasted 461 minutes, while the indexing alone without generating completions was done within 3 minutes. A cost of 2 orders of magnitude is certainly not acceptable. So we have to come up with a fundamentally better.
E.g. with the document A quick baseline experiment shows that deriving and counting all unique unigrams is inefficient.,
the following generated n-gram completions are unlikely queries to be entered by an user:a quickexperiment showsexperiment shows thatshows thatshows that derivingthat derivingthat deriving and
more likely queries would be:deriving unigramsderiving unigrams inefficientcounting unigramscounting unigrams inefficient
Additional considerations
- Only completions are created and counted, that appear as consecutive terms within a maximum distance of 3 (unigrams, bigrams, trigrams) within the indexed documents, in order to limit the RAM and disk consumption. The number and the length of extracted n-grams grows linearly with n, but the number of unique n-grams to store and search through grows exponentially with n.
- The maximum number of completion entries to be collected can be specified.
- By specifying from which fields of the documents the completions should be derived, e.g. from title field, product name field, the relevancy (precision) of completions can be increased, at the cost of completeness (recall).
Usually every field has a specific meaning or purpose, which we could understand as human labeling. It doesn’t make sense to lose that information away by throwing all fields in a bag of words, only to subsequently trying to recover again that meaning with global statistics. We could also use extra boost / scoring factors per field.
From result documents (SERP)
Another approach is extracting completions from previous search results, given that we are using instant search where we return results for every key stroke, or at least every term that has been completely entered.. If we search for “data encryption algor…” there has been previously the query “data encryption”. In the search results of that query we can analyze, what terms are following the matches of the query terms within each returned document. We are extracting completions on-the-fly from previously returned documents.
Again, there are pros and cons:
Benefits
- no extraction preprocessing of query log or corpus required
- no storage of completion lists required
Drawbacks
- for small result sets the extracted suggestions will be limited. The relevance of search results doesn’t ensure the relevancy and broadness of completions.
- for more complete and relevant suggestions we need to increase the result set of previous queries, introducing extra query latency and resource consumption.
- frequency data to small to reliably rank completions.
- extraction of completion from a large number of large result documents introduces extra suggestion latency.
Completion lookup methods
Once we have derived the completions, either form query logs or document corpus, we need to to lookup the matching completions for a given prefix or substring of an incomplete query. There are many feasible approaches, differing by result type, compactness and lookup time:
Prefix search
- Pruning radix trie
- Radix trie / patricia trie
- BTreeMap with ranges
- Ternary search tree
- other Tries
- Completion Trie (CT), Score-Decomposed Trie (SDT), and RMQ Trie (RT)
- DynSDT
Drawbacks of all tree/trie-based prefix-search algorithms:
- Not typo-tolerant
- Not word-order tolerant
If we reduce our requirements to single term completions, e.g. to completions of the last incomplete term of a query, we don’t need to generate a completion list first, and we simply can get away with a single-term frequency dictionary, like those used by SymSpell or those created in SeekStorm (if spelling correction is enabled) from the indexed documents.
The drawback would be twofold:
- we miss the convenience and time saving of multi-term completions
- the ranking of single term completions is less relevant, as we miss the co-occurrence probabilities of multi-term completions.
Typo-tolerant Prefix search
The idea is to combine prefix search via one of the trie data structures with the same Symmetric Delete algorithm that is used in SymSpell. Basically, instead of prefixes and terms, we use deletes of prefixes and terms.
Substring search
- Indexed Regular Expression Search based on character-wise 3-grams (trigrams), more, more.
A drawback of trigram-based substring search is the much larger index size, that is increased by factor L, with L being the average word length.
Conjunctive search
Conjunctive search identifies completions where all the query terms appear as prefixes of some of the terms of the completions, regardless their order.
Sliding window completion
Only completions were created that appear as consecutive terms within a maximum distance of 3 (unigrams, bigrams, trigrams) within the indexed documents, in order to limit the RAM and disk consumption.
To provide completions with n > 3 terms, we use a sliding window of the last three terms (the last term might be incomplete, any trailing space is counted as term) of the query string for lookup with prefix search within the collection of trigram completions. Then the first n-3 terms of the query are concatenated with each of the trigram completions found to create long completion candidates.
Validation
We need to verify whether the completion candidates are valid queries, e.g. by checking whether they indeed are returning results. The number of results per candidate can also be used for ranking the suggestions.
A less expensive, but also less reliable approach is to check whether all previous 3-gram searches (of complete terms) that were encountered during typing did return results.
Sliding window completion > 3 terms
Sliding window completion expansion
Sometimes we do get not enough suggestions (suggestions.len() < QueryRewriting::SearchSuggest{... length}) for a partial input query.
Example: without sliding window completion expansion:united states ol -> united states olympic

The reason for the limited results is that we search with a partial query of three terms only within trigrams.
If we detect that the number of returned suggestions is < length, then we add an an additional completion step with a different input.
We take the last two terms of the top trigram completion + space as input, to get more completions for long queries.
We are using the same principle as described in sliding window completion above, with the difference that now we search with the last two parts plus a trailing space of the first trigram completion,
while above we searched with the last three parts of the query.
Example: additional completion stepstates olympic -> united '+'olympic trials, united +states olympic curling, united +states olympic basketball, united +states olympic committee
The returned suggestions are not added to the end of the suggestion list, but inserted after the completion that was used as input.
Example: the final results after sliding window completion expansion:united states ol -> united states olympic, united states olympic trials, united states olympic curling, united states olympic basketball, united states olympic committee

Why don’t we start with the two last terms of the query from the beginning? The more terms we use as input the more likely the completions will match our intension. We only fall back if our first attempt doesn’t return enough results. Additionally, the last two terms from the top completion are more specific then the last two terms from the query where the last term is incomplete.
Another example: without sliding window completion expansion

Another example: with sliding window completion expansion

SymSpellComplete
We are combining query spelling correction, typo-tolerant Prefix search, Conjunctive search, and a sliding window for completion, and the lookup_compound method from SymSpell for spelling correction.
QAC using language models
Using language models for Query auto-completion is an promising approach.
While lexical query auto-completion tries to foresee the query the user is about to type, language model base query auto-completion tries to suggest queries that are different from what the user is going to type,
but better suited to the identified intention of the user, based on the actual index content.
We discarded this idea for now for the following reasons:
- Language models are language and domain specific, making it expensive in a multi-language, multi-domain, multi-tenancy environment.
- Language models are time consuming to update.
- Language models add significant complexity, processor load and latency, especially under high concurrent load.
- Increased recall, but at the cost of decreased precision.
- Problematic for misspelled input.
It boils down to the choice between giving up the last 10% of suggestion quality and completeness vs. orders of magnitude latency, system complexity, development time and production cost.
- A product-aware query auto-completion framework for e-commerce search via retrieval-augmented generation method
- Subword Language Model for Query Auto-Completion
Challenges
- How to merge and rank corrections vs. completions, if both are available?
- How to rank between unigrams/bigram/trigrams? Higher order n-gram counts are always lower compared with lower-order n-grams they are prefixed with. But perhaps the lower order n-gram isn’t a complete query and we should prefer the higher order n-gram that is? Between higher- and lower order n-grams with different prefixes it is even harder to decide. Do we need a correction factor for n-gram order?
Query spelling correction
SeekStorm’s query spelling correction is using the SymSpell library, based on the Symmetric Delete spelling correction algorithm.
WE use the lookup_compound method for the spelling correction of multi-term query strings that handles three cases:
- mistakenly inserted space into a correct term led to two incorrect terms:
hels inki->helsinki - mistakenly omitted space between two correct terms led to one incorrect combined term:
modernart->modern art - multiple independent input terms with/without spelling errors:
cinese indastrialication->chinese industrialization
The Symmetric Delete spelling correction algorithm reduces the complexity of edit candidate generation and dictionary lookup for a given Damerau-Levenshtein distance. It is six orders of magnitude faster (than the standard approach with deletes + transposes + replaces + inserts) and language independent.
Query spelling correction
Combining spelling correction and completion
The combination of query spelling correction and query auto-completion (QAC) can be challenging. Currently we use the following straight forward approach:
- We use the query as input for the query auto-completion (QAC).
- If no completions are returned then we switch to query spelling correction.
- If a spelling correction was found, then we use the corrected query as input for a second query auto-completion (QAC).
An alternative approach would be simpler, but also more prone to errors:
- We use all complete query terms as input for the query spelling correction, and remember the incomplete last term (enter or space make a term complete).
- We concatenate the result of the query spelling correction and the incomplete last term as input for query auto-completion (QAC).
While the second approach is simpler, it is also but also more prone to errors:
- If the spelling correction of the query returns an incorrect result, then the subsequent completion will also return incorrect or no completions.
- We have to consider
- the probabilities of a required spelling correction,
- the probabilities of a incorrect spelling correction result,
- the probabilities of an required completion,
- the additional latency of a spelling correction,
- the additional latency of a query completion,
- is the dictionary for spelling correction is complete or limited,
- is the list of completions is complete or limited.
- We almost always need to complete the query, while spelling errors are relatively rare.
When we start with query completion it won’t introduce errors, and at the same time we can avoid 90% of spelling correction calls (no additional latency, no chance of introducing errors).
If a spelling correction exists this indicates that the query is spelled correctly, allowing us to sidestep spelling correction.
Completions of corrected query
If we have found a correction of a misspelled query we can repeat the failed completion attempt, this time with the corrected query as input.
Of course, we have to make sure to prevent an endless loop (of unsuccessful completions and corrections).
Completion of corrected query
UI integration of Completions
Ghosting
Ghosting is the process of predicting, auto-completing and highlighting a user’s intended text input inline i.e., within the search box. Ghosting increases the acceptance of offered suggestions, reduces misspelled searches, and improves sales.
Instant search
During typing the incomplete query is automatically completed and the best suggestion is used as query for instant search, if the option SearchRewrite is enabled.
While immediately executing every partial query already counts as “instant search”, it becomes much more useful once it is combined with query auto-completion (QAC).
Then you are not only saving the final “Enter”, but you will see the final result much earlier, even if you have only typed a prefix.
This saves keystrokes, time, unnecessary searches of incomplete queries, and distracting the user with their irrelevant search results.
It is useful to prevent searches of different prefixes leading to identical completions, because it is not guaranteed that the user stops typing, once the desired completion is displayed.
The UI frontend can simply cancel all queries where the new partial query is a prefix of last completed query, but only if the new partial query is longer than the previous one (accounting for delete or browser back button).
This eliminates any unnecessary frontend-backend communication.
Query auto-completion (QAC), ghosting, and instant search
Completions and search operators
While using query completions we need to preserve any entered query operators, as + - “”.
Completions, tokenizers and stemming
Tokenizers and stemming influence influence how terms are stored and searched in the search index. They also influence how completions are extracted from the corpus. We have to make sure that indexing, search, completion generation and completion lookup all are using the same transformation pipeline.
Serialization and compression of completion lists
- https://en.wikipedia.org/wiki/Incremental_encoding
- https://en.wikipedia.org/wiki/Zstd
- https://github.com/rkyv/rkyv?tab=readme-ov-file
- https://en.wikipedia.org/wiki/Comma-separated_values
Removing outdated completions
Often an index is not static, new documents are indexed, outdated documents are removed. This is a very typical for e-commerce search. While new completions are covered, when they are anyway derived from newly indexed documents, for outdated we have to take one of the following extra measures:
- regularly, or after a certain time or number of deleted documents, re-generate all suggestions from all indexed documents. This is somewhat expensive and works only if fields not only index but also stored.
- for each deleted document, generate all completions for this document, and decrease their count in the list of stored suggestions. If the count reaches 0, then remove the completion (and all longer n-grams containing this suggestion) from the stored list.
- Let the user do the maintenance: if for a user query and their completions no results are found in the index, then this completion (and all longer n-grams containing this suggestion) are removed from the list of stored completions.
Scaling challenges
Both correction dictionaries and completion list face scaling challenges.
- The number of unique dictionary terms grows with the number of indexed documents according to Heap’s law.
- The number of unique deletes used in the symmetric delete spelling correction algorithm of SymSpell grows with the number of unique dictionary terms, multiplied with factor l=term length.
- The number of n-gram completions grows exponentially with the number of unique dictionary terms.
Especially challenging is to keep dictionary terms, deletes and n-gram completions in RAM for fast lookup time. As RAM is limited, compared to the index residing on disk, we won’t be able to keep all dictionary terms, deletes and n-gram completions in RAM.
Capping dictionary and completions at a certain limit during indexing will lead to several problems:
- New terms won’t it make to the dictionary, causing the spelling correction to identify it as spelling error and possibly causing a mis-correction to similar known terms.
- Likewise, for newer terms appearing later in time during indexing no query completion will be available.
This are not specific problems of deriving the dictionary and completions from the indexed documents, but scaling problems that static dictionary and completion lists would face as well.
Tests: What to measure?
It is easy to get something going, but we want to compare our solution with alternative approaches and we want to see whether different measures can improve our result. We have to reliably measure how close the results our system is producing are to this what we would be expecting if if we would hand-craft it ourselves.
Creation time
The time required to derive all significant completions up to a certain n-gram length from a document corpus of a given size.
Lookup time
The time to lookup matching completions for different query prefix lengths.
RAM consumption
RAM consumed during creation and use, e.g. bei hash maps and tries.
Disc space consumption
The disc space required to persistently store serialized completions.
Recall
The percentage of queries with matching completions, preferably with queries logged from real users.
Precision
The percentage of queries, for all prefixes of length 1..n, where the top-k completions we provided matched the final query.
User interaction
Measure the percentage of presented queries the user actually has interacted with.
Benchmarks
Usage
SymSpellComplete (standalone)
SeekStorm library (integrated SymSpellComplete)
Create Index
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
pub struct SpellingCorrection {
/// The edit distance thresholds for suggestions: 1..2 recommended; higher values increase latency and memory consumption.
pub max_dictionary_edit_distance: usize,
/// Term length thresholds for each edit distance.
/// None max_dictionary_edit_distance for all terms lengths
/// Some([4]) max_dictionary_edit_distance for all terms lengths >= 4,
/// Some([2,8]) max_dictionary_edit_distance for all terms lengths >=2, max_dictionary_edit_distance +1 for all terms for lengths>=8
pub term_length_threshold: Option<Vec<usize>>,
/// Maximum number of completions to generate during indexing
pub max_dictionary_entries: usize,
}
pub struct QueryCompletion {
/// Maximum number of completions to generate during indexing
/// disabled if == 0
pub max_completion_entries: usize,
}
pub struct IndexMetaObject {
...
/// Enable spelling correction for search queries using the SymSpell algorithm.
/// SymSpell enables finding those spelling suggestions in a dictionary very fast with minimum Damerau-Levenshtein edit distance and maximum word occurrence frequency.
/// When enabled, a SymSpell dictionary is incrementally created during indexing of documents and stored in the index.
/// The spelling correction is not based on a generic dictionary, but on a domain specific one derived from your indexed documents (only indexed fields).
/// This makes it language independent and prevents any discrepancy between corrected word and indexed content.
/// The creation of an individual dictionary derived from the indexed documents improves the correction quality compared to a generic dictionary.
/// An dictionary per index improves the privacy compared to a global dictionary derived from all indices.
/// The dictionary is deleted when delete_index or clear_index is called.
/// Note: enabling spelling correction increases the index size, indexing time and query latency.
/// Default: None. Enable by setting CreateDictionary with values for max_dictionary_edit_distance (1..2 recommended) and optionally a term length thresholds for each edit distance.
/// The higher the value, the higher the number of errors taht can be corrected - but also the memory consumption, lookup latency, and the number of false positives.
/// ⚠️ In addition to the create_index parameter `meta.spelling_correction` you also need to set the parameter `query_rewriting` in the search method to enable it per query.
pub spelling_correction: Option<SpellingCorrection>,
/// Enable query completion for search queries
pub query_completion: Option<QueryCompletion>,
}
pub struct SchemaField {
...
/// if both indexed=true and dictionary_source=true then the terms from this field are added to dictionary to the spelling correction dictionary.
/// if disabled, then a manually generated dictionary can be used: dictionary.csv
pub dictionary_source: bool,
/// if both indexed=true and completion_source=true then the n-grams (unigrams, bigrams, trigrams) from this field are added to the auto-completion list.
/// if disabled, then a manually generated completion list can be used: completions.csv
pub completion_source: bool,
...
}
create_index(
...
meta,
&schema,
...
).await
Search
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
pub enum QueryRewriting {
/// Query rewriting disabled, returns query results for query as-is, returns no suggestions for corrected or completed query.
/// No performance overhead for spelling correction and suggestions.
#[default]
SearchOnly,
/// Query rewriting disabled, returns query results for original query string, returns suggestions for corrected or completed query.
/// Additional latency for spelling suggestions.
SearchSuggest{
/// Enable query correction, for queries with query string length >= threshold
/// A minimum length of 2 is advised to prevent irrelevant suggestions and results.
correct:Option<usize>,
/// The edit distance thresholds for suggestions: 1..2 recommended; higher values increase latency and memory consumption.
distance:usize,
/// Term length thresholds for each edit distance.
/// None max_dictionary_edit_distance for all terms lengths
/// Some([4]) max_dictionary_edit_distance for all terms lengths >= 4,
/// Some([2,8]) max_dictionary_edit_distance for all terms lengths >=2, max_dictionary_edit_distance +1 for all terms for lengths>=8
term_length_threshold: Option<Vec<usize>>,
/// Enable query completions, for queries with query string length >= threshold, in addition to spelling corrections
/// A minimum length of 3 is advised to prevent irrelevant suggestions and results.
complete:Option<usize>,
/// An option to limit maximum number of returned suggestions.
length:Option<usize>
},
/// Query rewriting enabled, returns query results for spelling corrected or completed query string (=instant search), returns suggestions for corrected or completed query.
/// Additional latency for spelling correction and suggestions.
SearchRewrite{
/// Enable query correction, for queries with query string length >= threshold
/// A minimum length of 2 is advised to prevent irrelevant suggestions and results.
correct:Option<usize>,
/// The edit distance thresholds for suggestions: 1..2 recommended; higher values increase latency and memory consumption.
distance:usize,
/// Term length thresholds for each edit distance.
/// None max_dictionary_edit_distance for all terms lengths
/// Some([4]) max_dictionary_edit_distance for all terms lengths >= 4,
/// Some([2,8]) max_dictionary_edit_distance for all terms lengths >=2, max_dictionary_edit_distance +1 for all terms for lengths>=8
term_length_threshold: Option<Vec<usize>>,
/// Enable query completions, for queries with query string length >= threshold, in addition to spelling corrections
/// A minimum length of 3 is advised to prevent irrelevant suggestions and results.
complete:Option<usize>,
/// An option to limit maximum number of returned suggestions.
length:Option<usize>
},
/// Search disabled, returns no query results, only returns suggestions for corrected or completed query.
SuggestOnly{
/// Enable query correction, for queries with query string length >= threshold
/// A minimum length of 2 is advised to prevent irrelevant suggestions and results.
correct:Option<usize>,
/// The edit distance thresholds for suggestions: 1..2 recommended; higher values increase latency and memory consumption.
distance:usize,
/// Term length thresholds for each edit distance.
/// None max_dictionary_edit_distance for all terms lengths
/// Some([4]) max_dictionary_edit_distance for all terms lengths >= 4,
/// Some([2,8]) max_dictionary_edit_distance for all terms lengths >=2, max_dictionary_edit_distance +1 for all terms for lengths>=8
term_length_threshold: Option<Vec<usize>>,
/// Enable query completions, for queries with query string length >= threshold, in addition to spelling corrections
/// A minimum length of 3 is advised to prevent irrelevant suggestions and results.
complete:Option<usize>,
/// An option to limit maximum number of returned suggestions.
length:Option<usize>
},
}
/// * `query_rewriting`: Enables query rewriting features such as spelling correction and suggestions.
/// The spelling correction of multi-term query strings handles three cases:
/// 1. mistakenly inserted space into a correct term led to two incorrect terms: `hels inki` -> `helsinki`
/// 2. mistakenly omitted space between two correct terms led to one incorrect combined term: `modernart` -> `modern art`
/// 3. multiple independent input terms with/without spelling errors: `cinese indastrialication` -> `chinese industrialization`
/// See QueryRewriting enum for details.
/// ⚠️ In addition to setting the query_rewriting parameter per query, the incremental creation of the Symspell dictionary during the indexing of documents has to be enabled via the create_index parameter `meta.spelling_correction`.
async fn search(
...
query_rewriting: QueryRewriting,
) -> ResultObject;
SeekStorm server REST API (integrated SymSpellComplete)
Create Index
1
2
3
4
5
pub struct CreateIndexRequest {
...
pub spelling_correction: Option<SpellingCorrection>,
pub query_completion: Option<QueryCompletion>,
}
Search
1
2
3
4
pub struct SearchRequestObject {
...
pub query_rewriting: QueryRewriting,
}
Availability
This has been quite a ride, to get a seemingly simple idea right. Now you are invited to test and use our first iteration of Query Auto-Completion (QAC) and Instant Search. Advanced features, such as term-order-independent completions and completion of spelling-corrected partial queries, are scheduled for the next release. Both the SeekStorm lexical search library and multi-tenancy server and the SymSpellComplete auto completion library are implemented in Rust and released as open source under the Apache 2.0 license.